文字列関数
最終更新日: 2022年8月15日
半角カナで表現された口座名義の正規化処理を行います。検索揺れや、名寄せに適用できます。引数の文字列は半角カナ文字列で、戻り値の型は正規化された半角カナ文字列となります。
ACCOUNTKANANORM
ACCOUNTKANANORM(半角カナ文字が格納された文字列)

実行結果(デバッグログ)は次のとおりです。

詳細な変換ルールは次のとおりです。
- ハイフン等が連続で複数ある場合は、一つにまとめる。
- 「ヴ, ヂ, ヅ」を「ブ, ジ, ズ」に正規化する。
- "株式会社"、"有限会社"等の略号を除去する。
(*2) 対応する略号は次のとおりです。
"カ." "ユ." "メ." "シ." "キ." ".カ" ".ユ" ".メ" ".シ" ".キ" - 濁点、半濁点を除去する。
- 小文字(拗音・促音)を大文字に変換する。
- ハイフンを母音に変換する。
- 文字列中に"エ"("オ")段の文字が連続し、かつ二文字目が"エ"("オ")の場合、"エ"を"イ"へ、"オ"を"ウ"へ変換する。
- 半角ブランク(スペース)を削除する。
ASC
ASC(入力文字列)
全角の文字列を半角の文字に変換します。 具体的には「アルファベット」「数字」「記号」「カタカナ」が対象になります。

実行結果(デバッグログ)は次のとおりです。

CONCATENATE
CONCATENATE(文字列1, 文字列2)
引数の文字列を連結した文字列を返します。
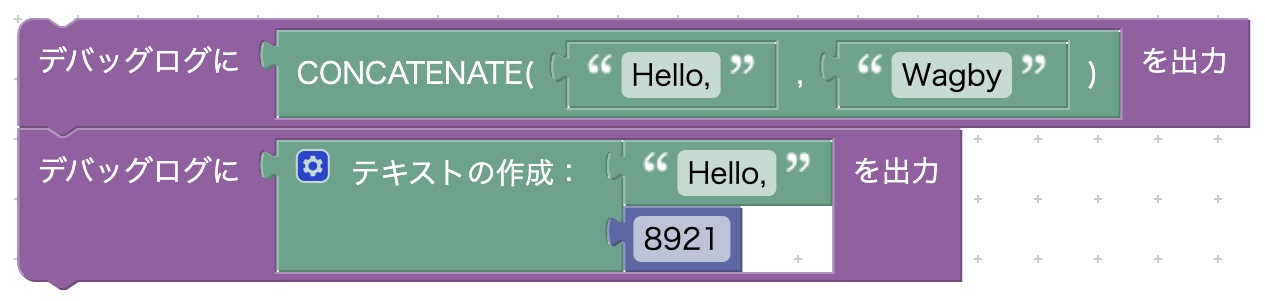
テキストの作成ブロックとの違い
テキストの作成ブロックは文字列だけでなく数値や日付を(文字列として)扱うことができるため、こちらの方が使いやすいです。一方、CONCATENATEブロックは文字列のみを扱います。
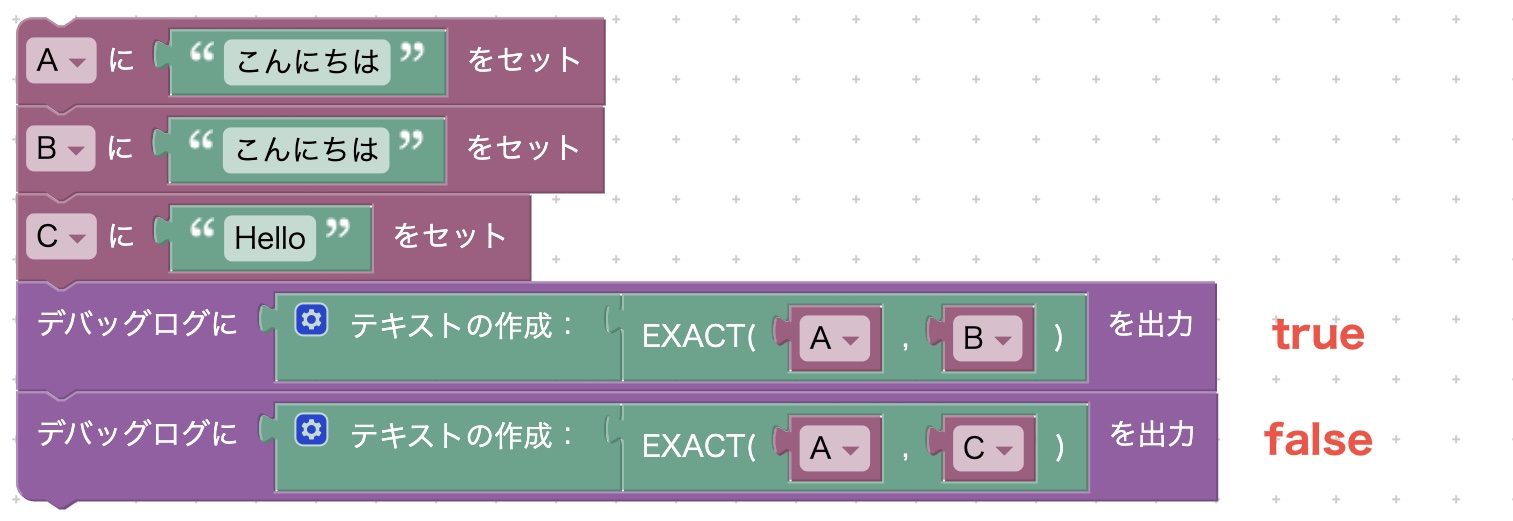
EXACT
EXACT(文字列1, 文字列2)
二つの文字列の比較を行います。同一ならtrueを返します。違っていた場合はfalseを返します。
FINDRE
FINDRE(検索文字列, 対象, 開始位置)
検索文字列が先頭から何番目にあるかを返します。戻り値の型は整数型です。検索文字列部分に正規表現が指定できます。
開始位置は 1 から開始してください。通常は 1 を指定します。英字の大文字と小文字は区別します。
次の例は ptr 変数の値が 7 になります。

ISBLANK
ISBLANK(文字列)
引数が NULL または空白かどうかを調べます。NULL または空白ならtrueを返します。そうでなければ(何らかの文字があれば)falseを返します。
ISINCLUDE
ISINCLUDE(文字列1,文字列2)
第一引数の値に、第二引数のいずれかの文字が含まれていれば true を返します。
次の例は 'a','i','u','e','o' のいずれかが含まれているのでtrueになります。

JIS
JIS(入力文字列)
半角の文字列を全角の文字に変換します。 具体的には「アルファベット」「数字」「記号」「カタカナ」が対象になります。

実行結果(デバッグログ)は次のとおりです。

JOIN
JOIN(文字列リスト, 区切り文字)
リスト内の文字列の各要素を、区切り文字で連結した文字列を返します。 文字列配列が空の場合、長さ0の空文字列 "" を返します。
「リストからテキストを作る」ブロックの違いは、空白要素の扱いにあります。JOIN関数は空白要素を無視します。
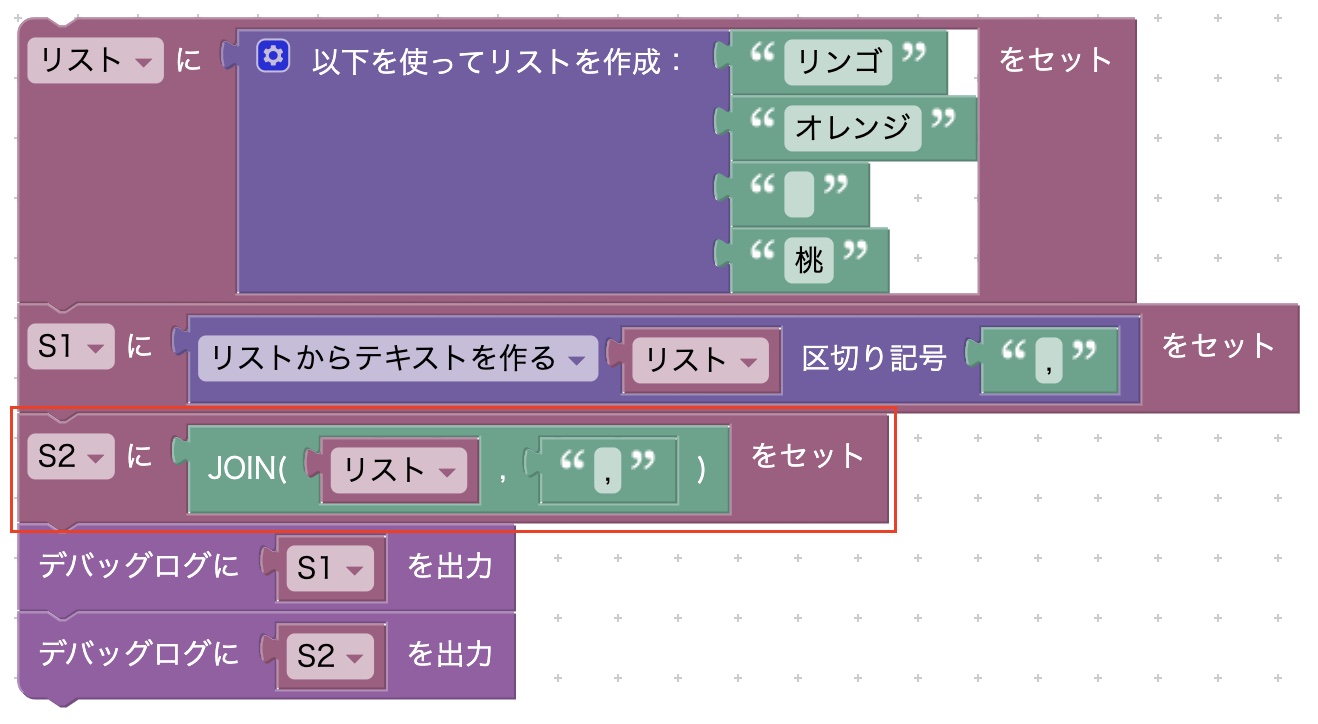
実行結果(デバッグログ)は次のとおりです。

JOINと対になる関数がSPLITです。
JPKANANORM
JPKANANORM(カナ文字が格納された文字列)
濁音、拗音を清音に正規化します。例えば「ヤマダ」という文字列が「ヤマタ」になります。戻り値の型は文字列型です。
詳細な変換ルールは次のとおりです。
入力文字:ヴガギグゲゴザジズゼゾダヂヅデドバビブベボパピプペポァィゥェォャュョヵヶッ
出力文字:ウカキクケコサシスセソタチツテトハヒフヘホハヒフヘホアイウエオヤユヨカケツ

実行結果(デバッグログ)は次のとおりです。

LOWER
LOWER(文字列)
アルファベットの大文字を小文字に変換します。戻り値の型は文字列型です。

実行結果(デバッグログ)は次のとおりです。

LPAD
LPAD(文字列, 指定桁数, 埋め込み文字)
文字列の左側に、指定桁数になるまで埋め込み文字を挿入します。

実行結果(デバッグログ)は次のとおりです。

MAILADDRESS
MAILADDRESS(文字列)
RFC822フォーマットに準拠したメールアドレスを表す文字列から、メールアドレス部を抽出します。

実行結果(デバッグログ)は次のとおりです。

MID
MID(文字列, 開始値, 文字数)
MID(文字列, 開始値)
文字列の任意の位置から指定された文字数の文字を返します。先頭文字の位置が 1 になります。戻り値の型は文字列型です。
第三引数(文字数)を省略した場合は、開始値以降のすべての文字列が返されます。

実行結果(デバッグログ)は次のとおりです。

NUMTOJTEXT
NUMTOJTEXT(数字, 区切りパターン, 文字種)
NUMTOJTEXT(数字を表す文字列, 区切りパターン, 文字種)
数字を日本語のテキストに変換します。戻り値の型は文字列です。
区切りパターンは次の4種類があります。
- 0 : 区切りパターンなし
- 1 : 3桁毎(千単位)
- 2 : 万および億単位
- 3 : 十、百、千、万および億単位
文字種パターンは次の4種類があります。
- 0 : 半角数字
- 1 : 全角数字
- 2 : 漢数字(一、二、三)
- 3 : 旧漢字(壱、弐、参)
| 例 | 返される文字列 |
|---|---|
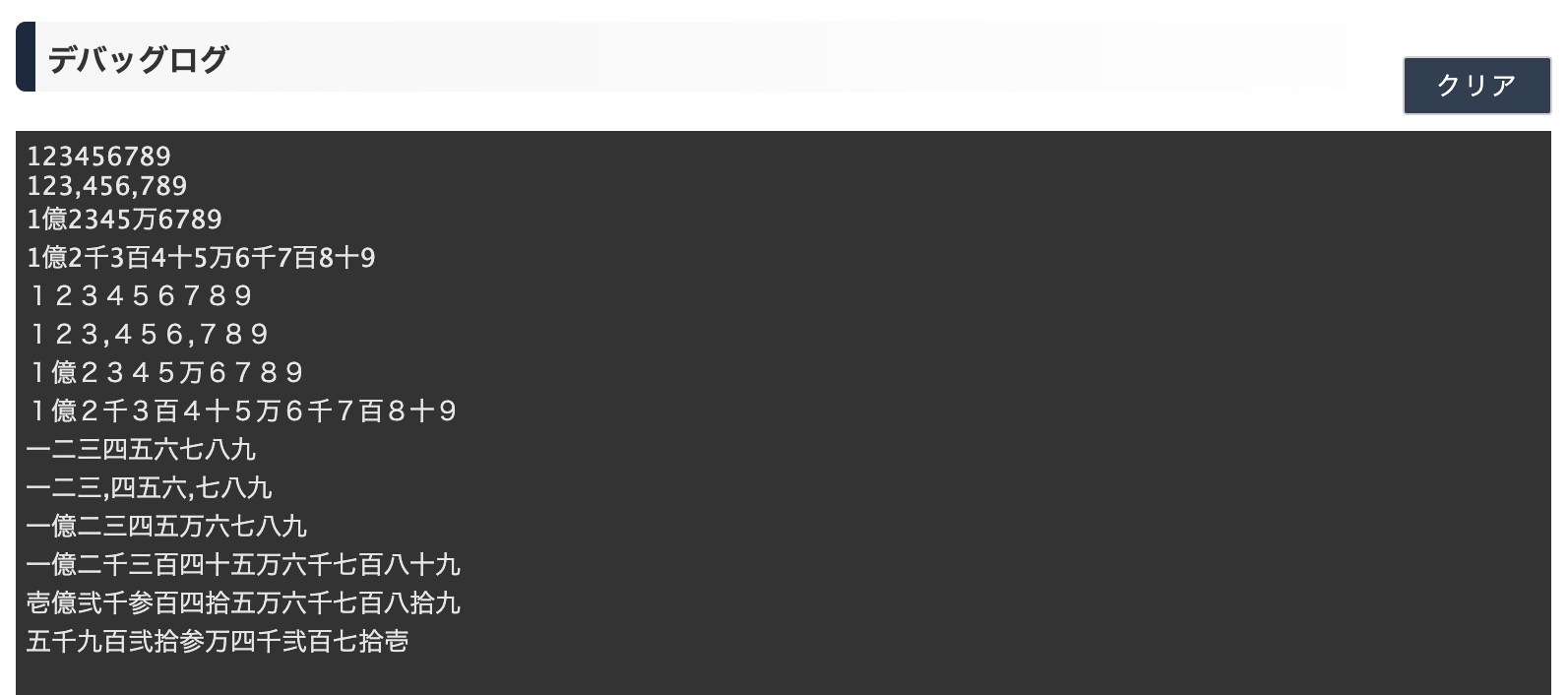
| NUMTOJTEXT(123456789, 0, 0) | "123456789" |
| NUMTOJTEXT(123456789, 1, 0) | "123,456,789" |
| NUMTOJTEXT(123456789, 2, 0) | "1億2345万6789" |
| NUMTOJTEXT(123456789, 3, 0) | "1億2千3百4十5万6千7百8十9" |
| NUMTOJTEXT(123456789, 0, 1) | "123456789" |
| NUMTOJTEXT(123456789, 1, 1) | "123,456,789" |
| NUMTOJTEXT(123456789, 2, 1) | "1億2345万6789" |
| NUMTOJTEXT(123456789, 3, 1) | "1億2千3百4十5万6千7百8十9" |
| NUMTOJTEXT(123456789, 0, 2) | "一二三四五六七八九" |
| NUMTOJTEXT(123456789, 1, 2) | "一二三,四五六,七八九" |
| NUMTOJTEXT(123456789, 2, 2) | "1億二三四五万六七八九" |
| NUMTOJTEXT(123456789, 3, 2) | "一億二千三百四十五万六千七百八十九" |
| NUMTOJTEXT(123456789, 3, 3) | "壱億弐千参百四拾五万六千七百八拾九" |
| NUMTOJTEXT("59234271", 3, 3) | "五千九百弐拾参万四千弐百七拾壱" |
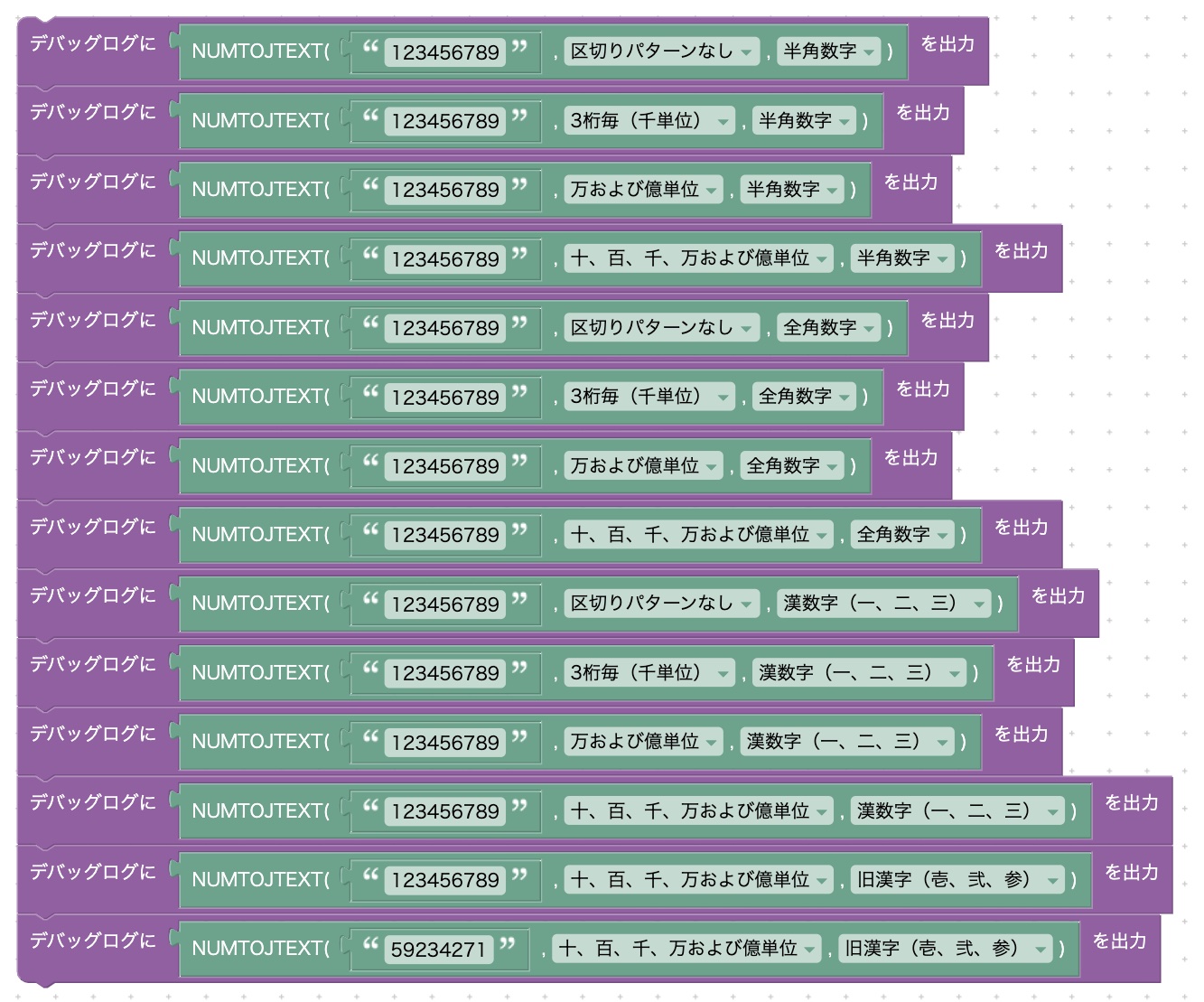
実行結果(デバッグログ)は次のとおりです。
制約
- 動作する数値は13桁までとなっています。
- 国際化には未対応です。日本語のみを対象としています。
PADDING
PADDING(埋める1文字, 桁数, 文字列)
引数の文字列の前に「埋める1文字」を加えます。全体で「桁数」の範囲内の文字列にします。 「埋める1文字」はダブルクォートで囲みます。(二文字以上が指定された場合、先頭の文字が有効になります。)
引数の文字列が、すでに桁数を超えていた場合、「埋める1文字」は無視され、全体で桁数の範囲内に調整されます。

実行結果(デバッグログ)は次のとおりです。

PROPER
PROPER(文字列)
アルファベットの 1 文字目を大文字に、2 文字目以降を小文字に変換します。戻り値の型は文字列型です。

実行結果は "Hello, wagby!" となります。
RANDSTR
RANDSTR(桁数)
RANDSTR(桁数,除外する文字列)
英大文字、小文字、数字から構成されるランダムな文字列を生成します。
第二引数は「除外する文字列」を指定します。この引数を省略した場合、除外する文字列として標準で "iIl1Oo0" が指定されます。これは似たような文字を除くことで視認性を高める措置です。
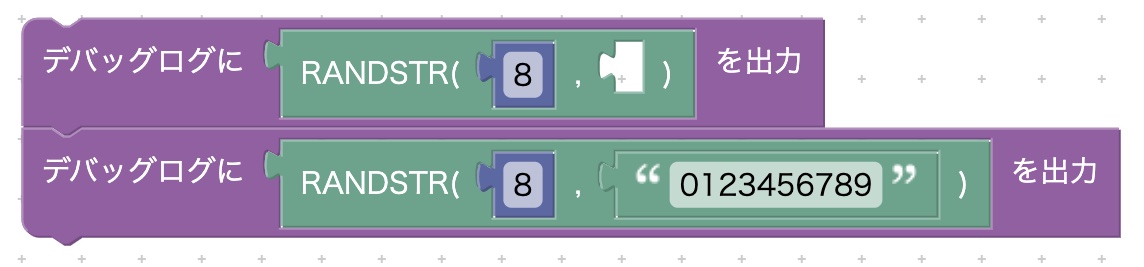
実行結果(デバッグログ)は次のとおりです。上の例は除外文字列を空と指定したため、すべての文字列を対象としたランダム文字列を生成します。下の例は数字を除く 8 桁のランダムな文字列を生成します。

REMOVEHTMLTAG
REMOVEHTMLTAG(対象文字列)
REMOVEHTMLTAG(対象文字列, 改行コード)
リッチテキストエリア項目の文字列中に含まれるHTMLタグを除去します。戻り値の型は文字列型です。
brタグは改行コードに置換されます。第二引数を省略した場合、改行コードは "\r\n" が利用されます。(Windows標準)。個別に "\r" (Mac) や "\n" (Linux) と指定することもできます。

リッチテキストエリアで装飾した文字列は、REMOVEHTMLTAGを通すことで、すべての装飾がなくなります。
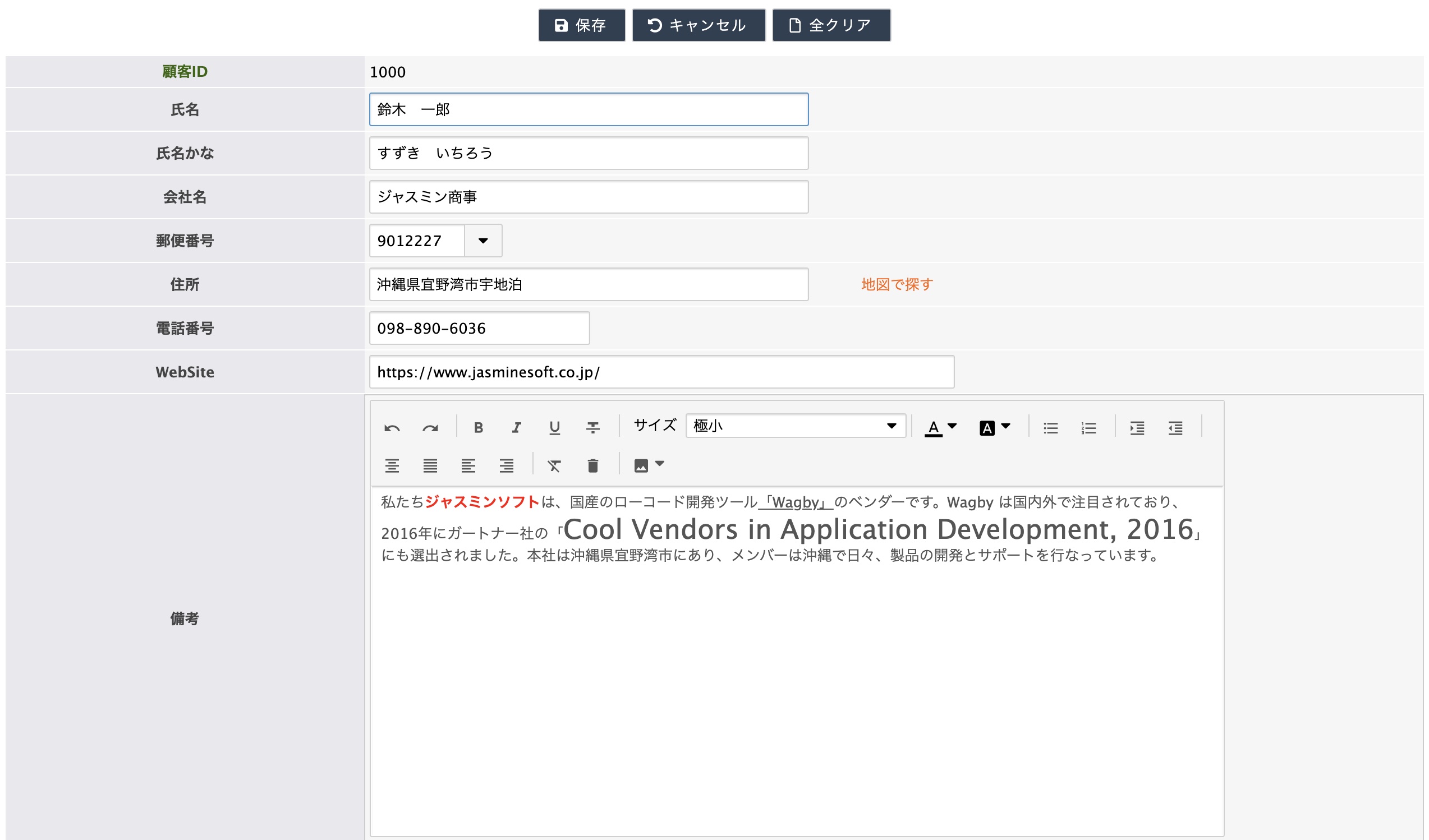
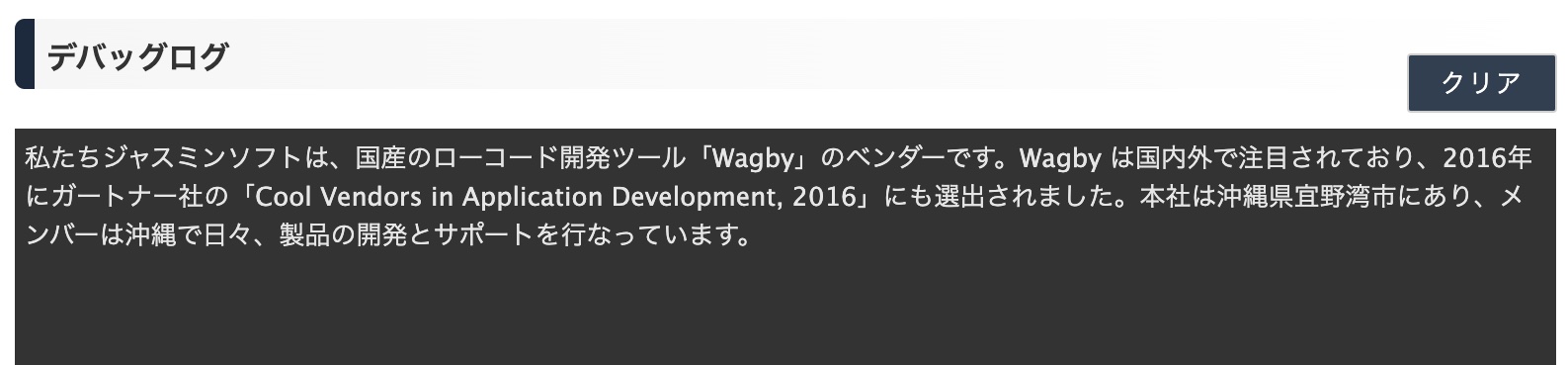
RPAD
RPAD(文字列, 指定桁数, 埋め込み文字)
文字列の右側に、指定桁数になるまで埋め込み文字を挿入します。

上の結果は "ABC000" になります。
SPLIT
SPLIT(対象文字列)
対象文字列を、区切り文字で分割します。区切り文字を省略したときは、半角スペースを区切り文字とします。戻り値の型は文字列の配列です。

「テキストからリストを作る」ブロックとは次の違いがあります。入力文字列を次のようにします。区切り文字はいずれも "," とします。
リンゴ ,オレンジ, ,,,,桃| 「テキストからリストを作る」ブロック | リンゴ ,オレンジ, ,,,,桃 |
|---|---|
| SPLITブロック | リンゴ, オレンジ, , 桃 |
またSPLITでは、区切られた個々の文字列の、前後の空白は削除されます。
SPLITと対になる関数がJOINです。
区切り文字を複数指定する
区切り文字を複数指定することができます。次の例は「,」「;」のいずれも区切り文字として扱います。

SUBSTITUTE
SUBSTITUTE(対象文字列, 検索文字列, 置換文字列)
文字列中から検索文字列を探し、置換文字列に置き換えます。戻り値の型は文字列型です。

上のスクリプトの結果は "こんにちは、Wagbee!" になります。
TOLONG
TOLONG(文字列)
文字列表現された数字を整数へ変換します。
| 入力値 | 出力値 |
|---|---|
| null | null ※nullを返す。 |
| "" | null ※空文字はnullとする。 |
| "100" | 100 ※文字列を数字に変換する。 |
| "10,000" | 0 ※コンマ区切りは解釈しない。 |
| "1.0" | 0 ※ピリオド付き文字列は解釈しない。 |
| 12.9 | 13 ※もっとも近い整数に丸める。 |
| true | 1 ※trueを1と解釈する。 |
| false | 0 ※falseを0と解釈する。 |
TODOUBLE
TODOUBLE(文字列)
文字列表現された数字を小数へ変換します。
| 入力値 | 出力値 |
|---|---|
| null | null ※nullを返す。 |
| "" | null ※空文字はnullとする。 |
| "100" | 100.0 ※文字列を数字に変換する。 |
| "10,000" | 0.0 ※コンマ区切りは解釈しない。 |
| "123.45" | 123.45 ※ピリオド付き文字列は解釈する。 |
| 10000000000l | 1.0E10※指数表現。 |
| true | 1.0 ※trueを1と解釈する。 |
| false | 0.0 ※falseを0と解釈する。 |
TOSTR
TOSTR(数値)
TOSTR(日付)
数値型/日付型の値を文字列型に変換します。TEXT関数と異なり、書式指定を行うことはできません。 計算結果を文字型項目にセットするといった目的に使うことができます。
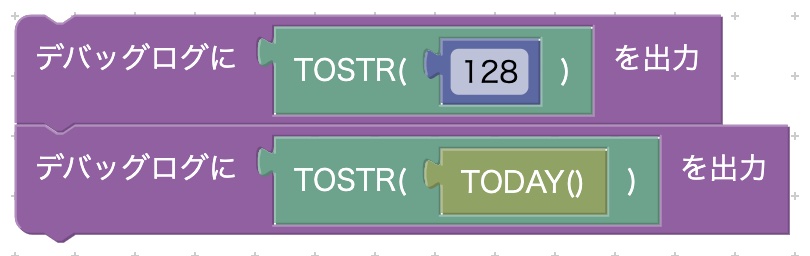
実行結果(デバッグログ)は次のとおりです。

UPPER
UPPER(文字列)
アルファベットの小文字を大文字に変換します。戻り値の型は文字列型です。

結果は "HELLO, WAGBY!" になります。
URLENCODE
URLENCODE(文字列)
引数の文字列をURLの表記規則にあわせて変換した文字列を返します。
| 入力文字列 |
|---|
| 沖縄県宜野湾市宇地泊902-1 |
| URLエンコードされた文字列 |
| %e6%b2%96%e7%b8%84%e7%9c%8c%e5%ae%9c%e9%87%8e%e6%b9%be%e5%b8%82%e5%ae%87%e5%9c%b0%e6%b3%8a902%2d1 |
VALUE
VALUE(文字列)
VALUE(文字列, デフォルト値)
数値を表す文字列を数値に変換します。日付、時間を表す文字列は日付(時間)シリアル値に変換します。戻り値の型は小数です。
第一引数の文字列が null または解析不可能な値の場合、デフォルト値が用いられます。省略時は Double.NAN(不定)となります。デフォルト値は第二引数で与えることができます。型は小数です。
| VALUE("0.12") | 0.12 |
| VALUE("1,234") | 1234 |
| VALUE("1,234.567") | 1234.567 |
| VALUE("1,23E-4") | 0.000123 |
| VALUE("12%") | 0.12 |
| VALUE("15:30") | 0.6458333333333334 |
| VALUE("2022-07-01 12:34:56") | 44743.52425925926 |
| VALUE("2022年7月1日") | 44743 |

実行結果(デバッグログ)は次のとおりです。
