項目の型に応じたルール
繰り返し項目
データの個数分項目名の後に番号が付与されます。
具体的には項目名[1]、項目名[2]・・・となります。
 図1 ダウンロードされたCSVファイルの例(1)
図1 ダウンロードされたCSVファイルの例(1)
繰り返しコンテナ
データの個数分項目名の後に番号が付与されます。
コンテナ名[1]/項目名、コンテナ名[2]/項目名・・・となります。
 図2 ダウンロードされたCSVファイルの例(2)
図2 ダウンロードされたCSVファイルの例(2)
文字列型
改行コードが含まれている場合、改行コードは維持されて CSV/Excel ファイルに出力されます。[トラブルシューティング...]
数値型
数値フォーマットは適用されません。
日付・時刻・日付時刻型
CSV形式の場合、日付・時刻・日付時刻型のフォーマットは適用されます。
Excel形式の場合、日付・時刻・日付時刻型のフォーマットは "JDBCタイムスタンプ・エスケープ形式" となります。それぞれ "yyyy-mm-dd", "h:mm:ss", "yyyy-mm-dd h:mm:ss" です。
ファイル型
ファイル名が取得できます。
モデル参照(リストボックス、ラジオボタン、検索画面)
項目の内容部が表示されます。(上図1の青枠部分)
登録がない場合は、データ部は空白で出力されます。
モデル参照(チェックボックス)
定義した項目名の後に参照内容が出力されます。二行目以降は、選択した内容の箇所に "1" が出力されます。
選択していない場合は "0" が出力されます。(上図2の青枠部分)
同じ項目名が定義されていた場合
区別するため、日本語の項目名の後に "(" + 項目ID + ")" が出力されます。(図3)
 図3 ダウンロードされたCSVファイルの例(3)
図3 ダウンロードされたCSVファイルの例(3)
ワンポイント
項目名が重ならないような設定を行うことで、この動作を抑制できます。
モデル参照(チェックボックス)で、項目名と先頭部分が一致する(他の)項目が定義されていた場合
区別するため、項目名の後に "(" + 項目ID + ")" が出力されます。(図4)
 図4 ダウンロードされたCSVファイルの例(4)
図4 ダウンロードされたCSVファイルの例(4)
データ権限機能を指定したモデル
データ権限を設定したモデルには「データ所有者」を示すための項目 "jgroupidjshparam" が含まれます。この項目は Wagby 内部で必要になります。
ダウンロード画面の設定
定義方法
ページタイトルと説明文を指定することができます。(図5)
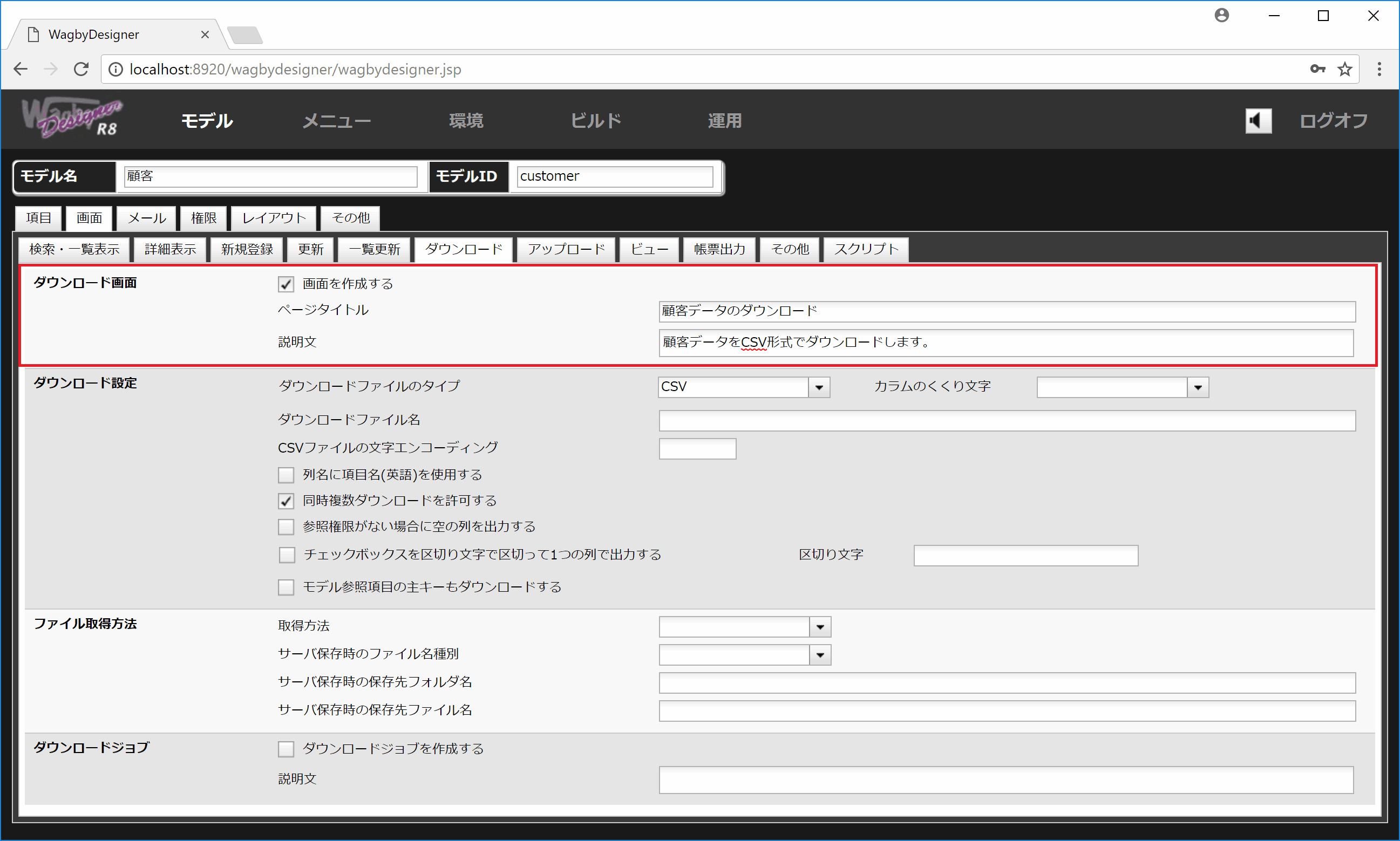 図5 ダウンロード画面に関する設定
図5 ダウンロード画面に関する設定
例
図5の設定で生成された画面を図6に示します。
 図6 ページタイトルと説明文を設定した例
図6 ページタイトルと説明文を設定した例
ダウンロード機能の設定
ダウンロード設定の詳細を説明します。
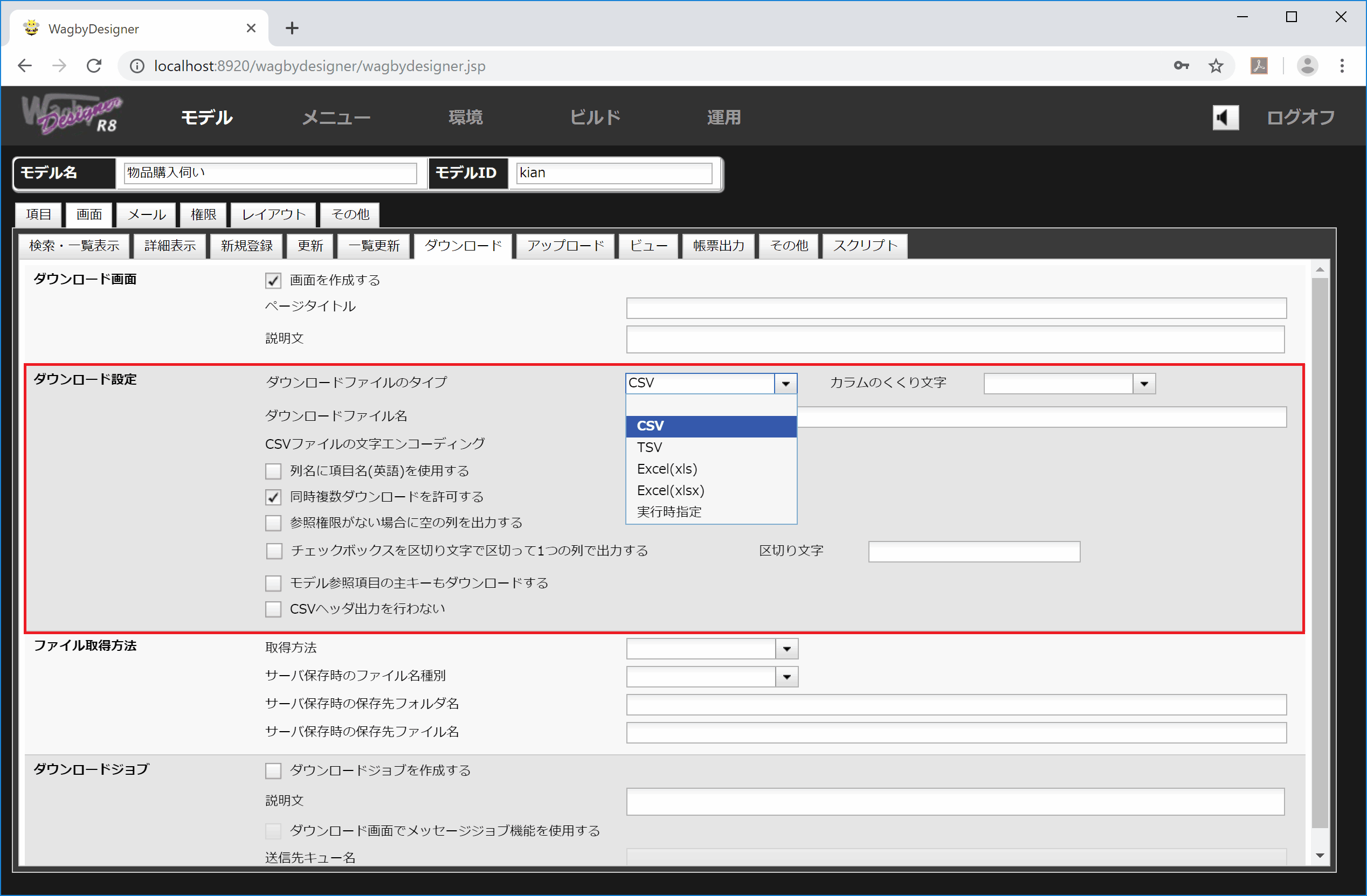 図7 ダウンロード機能に関する設定
図7 ダウンロード機能に関する設定
ダウンロードファイルのタイプ
"CSV(カンマ区切り)", "TSV(タブ区切り)", "Excel(xls)", "Excel(xlsx)", "実行時指定" が選択できます。
ダウンロードファイル名
ダウンロードするファイルの名前を任意に指定することができます。
詳細は"ダウンロードファイル名の設計"をお読みください。
CSVファイルの文字エンコーディング
モデル毎にダウンロードファイルの文字エンコードを指定することができます。この値が空白のときは「環境 > アプリケーション > 初期パラメータ > CSVファイルの文字エンコーディング」の値が用いられます。
例えば UTF-8 で出力したい場合はこの欄に utf-8 と記述します。
列名に項目名(英語)を使用する
チェックすると、ヘッダ部の項目名が項目IDに変わります。
同時複数ダウンロードを許可する
同時に複数の利用者がダウンロードを行うことができます。本設定は標準で有効になっており、無効にすることができません。
参照権限がない場合に空の列を出力する
参照権限がない項目は、項目名およびデータは表示されません。しかし本設定を有効にすると権限がない場合でも項目名は出力されるようになります。データは空白で出力されます。
チェックボックスを区切り文字で区切って1つの列で出力する
チェックボックス型ではデータ項目に対して "1" または "0" が出力されます。(図3)
本設定を有効にすると、データを一つにまとめて出力します。データ同士の区切り文字は "," を使います。例えば "官公庁,その他" のように出力します。
チェックボックスを区切り文字で区切って1つの列で出力する - 区切り文字
上述した「チェックボックスを区切り文字で区切って1つの列で出力する」の区切り文字を指定することもできます。空白時は "," (カンマ) が用いられます。
モデル参照項目の主キーもダウンロードする
モデル参照の項目は内容部が出力されます。本設定を有効にすると参照先モデルの主キーも同時に出力することができます。
主キーの項目は "項目名#id" となります。
カラムのくくり文字
標準ではダウンロードファイル中、カラムの前後にダブルクォーテーションが付与されます。本設定欄に「(なし)」を指定すると、ダブルクォーテーションを出力しません。本設定の未指定時(標準)はダブルクォーテーションです。
重要
カラムのくくり文字を「なし」とした場合、データ中にダブルクォーテーションやカンマが含まれないようにしてください。含まれていた場合、CSVファイルを受け取った側で解釈エラーが生じます。
ワンポイント
カラムのくくり文字がないCSVファイルを、アップロード更新することもできます。この場合もデータ中にダブルクォーテーションやカンマが含まれないようにしてください。
CSVヘッダ出力を行わない
出力するCSVファイルの先頭に含まれるヘッダ行を出力しません。先頭行からデータとなります。
ダウンロードファイル名の設計
空白時
ダウンロードファイル名を空白としたとき、ファイル名は次のルールに従います。
ログオンアカウント_data_All_日付時刻.拡張子
固定ファイル
固定ファイル名を指定することができます。拡張子は不要です。ファイル名は次のようになります。
プレースホルダ
検索条件をプレースホルダとして含めることができます。"モデル名_cp.項目名" となります。拡張子は不要です。
例を示します。
プレースホルダと他の文字を混在することもできます。
${report_cp.title}_${report_cp.type}_ファイル
式
ファイル名の設定欄に式(関数)を含めることはできません。そこで次のようにします。
- 検索条件に、隠し項目を用意する。
- 同項目の初期値(検索時)に式を用いてファイル名を決定する。
- この項目をプレースホルダとして用いる。
サンプル
サンプルのモデル定義を図8に示します。項目ID "csvfilename" は、ダウンロードするファイル名が格納される項目とします。
 図8 ダウンロードファイル名を保持するサンプルモデル
図8 ダウンロードファイル名を保持するサンプルモデル
この項目はデータベースに保存しません。(図9)
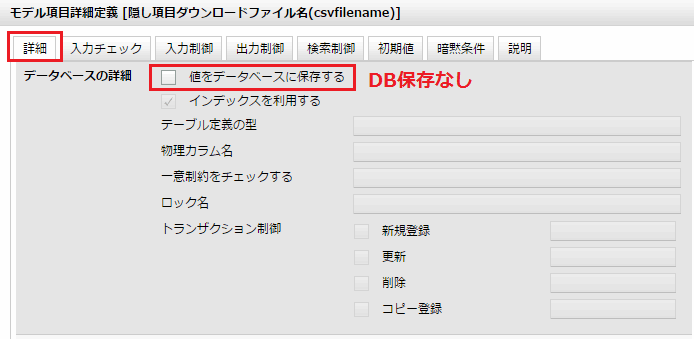 図9 データベース非保存とする
図9 データベース非保存とする
この項目は入力時に隠し項目とします。(図10)
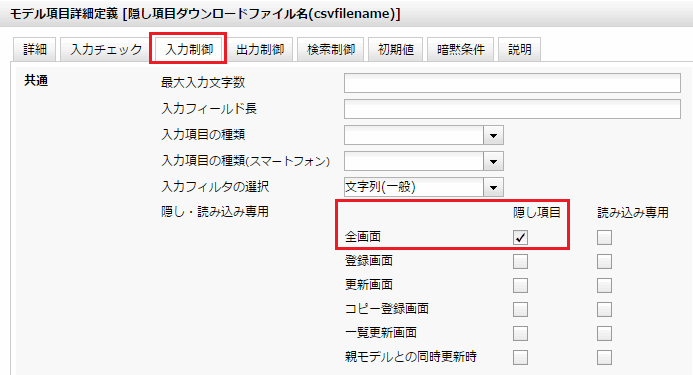 図10 入力時に隠し項目とする
図10 入力時に隠し項目とする
この項目は出力時にも隠し項目とします。(図11)
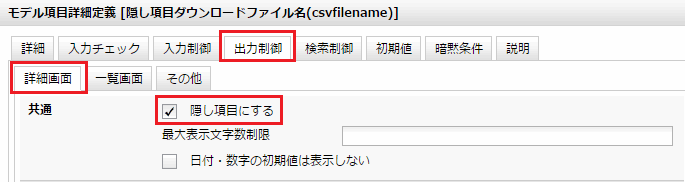 図11 出力時に隠し項目とする
図11 出力時に隠し項目とする
この項目は検索時にも隠し項目とします。(図12)
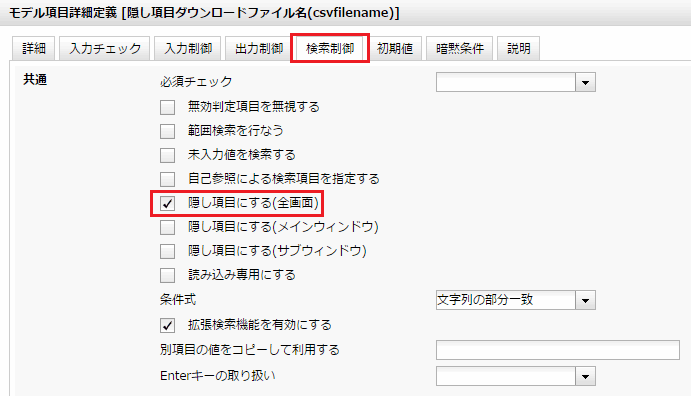 図12 検索時に隠し項目とする
図12 検索時に隠し項目とする
検索時の初期値に式を指定します。これがファイル名になります。(図13)
次の例は、検索条件時のname項目が空であればログオンアカウント名を使います。そうでなければ検索条件欄に入力されたname項目の値を使います。その後ろに日付を "yyyy-MM-dd" 書式で加えるものです。
IF(ISBLANK(${name}),USERNAME(),${name})+TEXT(TODAY(),"yyyy-MM-dd")
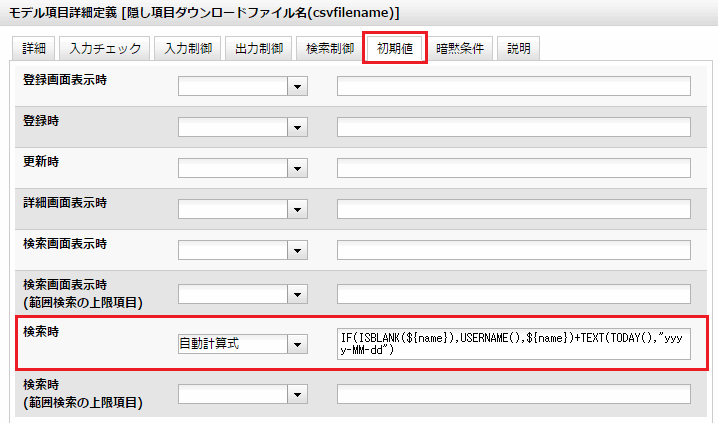 図13 式の設定
図13 式の設定
「画面 > ダウンロード > ダウンロード設定 > ダウンロードファイル名」には、この隠し項目を指定します。
${customer_cp.csvfilename}
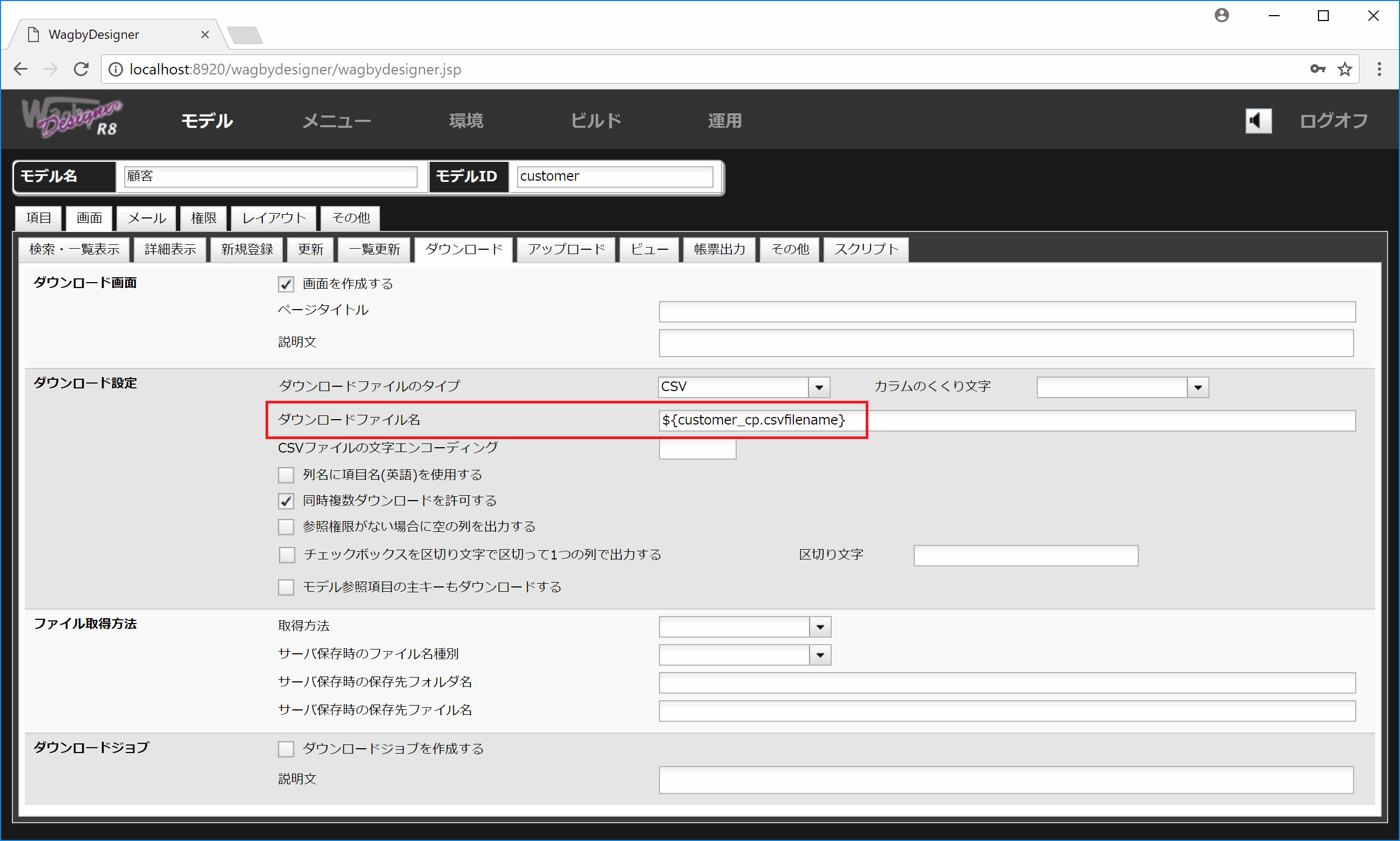 図14 ダウンロードファイル名の設定
図14 ダウンロードファイル名の設定
項目の設定
ダウンロードの対象に含める
各項目をダウンロードの対象に含めるかどうかを個別に指定できます。
「モデル項目詳細定義>出力制御>その他」の「CSVに出力する」を制御します。標準では有効となっています。
 図15 項目の出力設定
図15 項目の出力設定
並び順
出力されるデータの並び順は、次のようになります。
| 初期状態 | リポジトリで指定したソート順に従う。 |
| 利用者がブラウザでソート順を指定したとき |
指定が反映される。 |
繰り返し項目・繰り返しコンテナ項目の扱い
モデルに繰り返し項目および繰り返しコンテナが含まれる場合、これらのデータを独立してダウンロードすることができます。
図16は、繰り返し項目「電子メール」ならびに繰り返しコンテナ項目「商談履歴」を含むモデルです。
検索条件下部の「ダウンロード形式」で出力する内容を選択することができます。
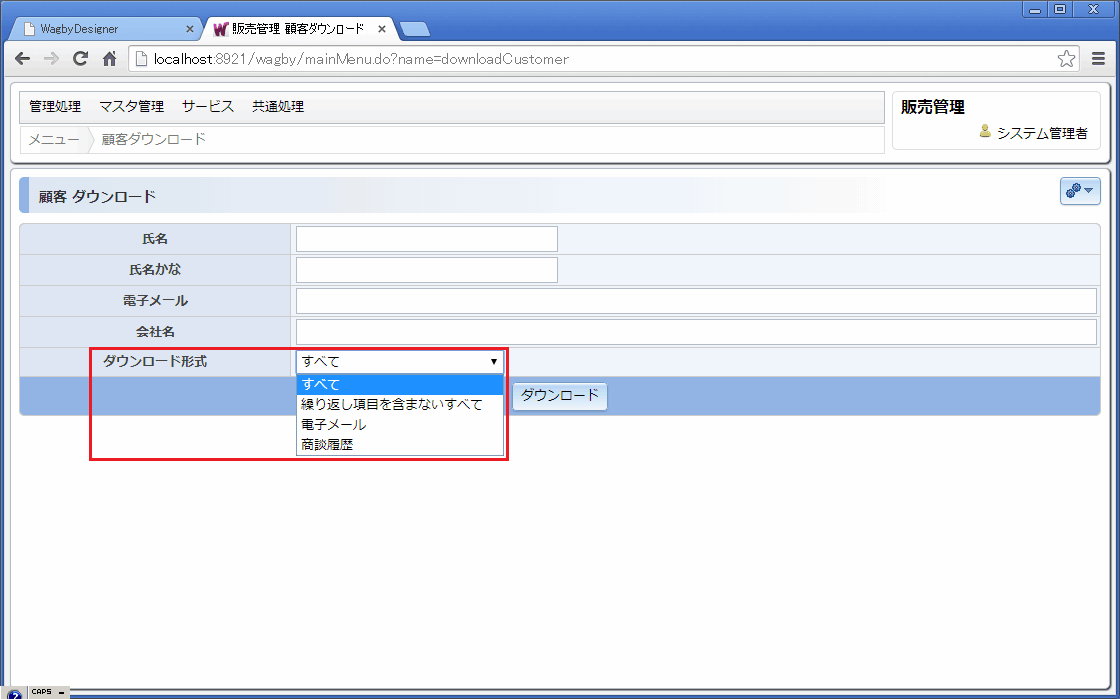 図16 繰り返し項目を含むモデルのダウンロード画面
図16 繰り返し項目を含むモデルのダウンロード画面
繰り返しコンテナ「商談履歴」をダウンロードし、Excelで開いた例を図17に示します。
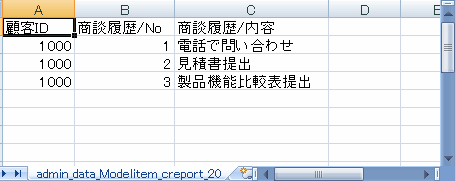 図17 繰り返しコンテナ「商談履歴」をダウンロードした例
図17 繰り返しコンテナ「商談履歴」をダウンロードした例
"すべて" をダウンロードした場合、繰り返し項目・繰り返しコンテナ項目がすべて一行にまとめて出力されます。(図1,図2)
繰り返し項目や繰り返しコンテナ項目を独立してダウンロードすると、行毎に展開して出力されます。(図17)
ファイル名の命名規則は次のようになります。
ログオンアカウント_data_Modelitem_繰り返し項目ID_日付時刻.拡張子
ログオンアカウント_data_Modelitem_繰り返しコンテナ項目ID_日付時刻.拡張子
ファイル名の命名規則を変更することはできません。
「ダウンロード形式」を表示しない
モデルに繰り返し項目または繰り返しコンテナがあり、かつ、これらがダウンロード対象となっていた場合、「ダウンロード形式」は必ず用意されます。これを非表示とする設定はありません。
そのため、この項目を非表示とするためには次のような方法で回避してください。
- 繰り返し項目または繰り返しコンテナ項目をダウンロード対象にしない。
- これらを除いたサブモデルを作成する。
子モデルの扱い
親子モデル関係において、親モデルと子モデルのデータはそれぞれ独立してダウンロードしてください。親モデルのダウンロードで、紐づく子モデルをまとめてダウンロードすることはできません。
ダウンロードファイルの取り扱いに関するルール
CSV, TSV ファイルをExcelで開く場合
CSV(カンマ区切り),TSV(タブ区切り)ファイルをダブルクリックするとExcelが起動する環境では、次の問題が生じることがあります。
- 先頭0詰めの数字で0が抜け落ちる。
- 任意の文字列としての項目の内容がたまたま日付の形式に近いと、自動的に日付型に自動変換されてしまう。
この問題を回避する方法は次のとおりです。
- ファイルのアイコン上で右クリックし、「プログラムから開く」から「Microsoft Office Excel」を指定する。
- 前もってExcelを起動しておき、開きたいファイルをドラッグ&ドロップする。
- Excelが提供する「データの取り込み」機能を使う。[後述]
Excelファイル
Excel形式でダウンロードしたファイルは、型の情報が反映されます。
- 文字列型、数値型、日付型は Excel のセルの型に反映されます。
- 数値型、日付型のフォーマット指定は、Excel に反映されません。(Wagbyの指定方法とExcelの指定方法が同一ではないため)
- モデル参照型の項目は、すべて文字列型として扱われます。
- 参照連動型の項目は、参照先の型がExcel のセルの型に反映されます。
重要
Excel形式でダウンロードする場合、一時的に大量のメモリを消費します。また、データの作成に非常に時間がかかることがあります。そのため、データ量によってはダウンロード処理が失敗する場合があります。
大量データを扱う場合はダウンロードするデータを(検索によって)絞込むようにしてください。または Excel 形式ではなく、CSV 形式に代えて運用してください。
.xls と xlsx の違い
拡張子 xls 形式を選択した場合、256列までのデータ項目を扱うことができます。(256列を超える部分は無視されます。)
取り扱うことができるデータ数の上限は 65,536 行です。
拡張子 xlsx 形式を選択した場合、16,384列までのデータ項目を扱うことができます。
取り扱うことができるデータ数の上限は 1,048,576 行です。
権限管理機能との組み合わせ
項目に権限設定を行った場合は次のように動作します。
- 項目名の出力は、権限のみが判定材料となります。条件付き権限を設定されていた場合も条件部は無視されます。
- 値の出力は、条件部に応じて出力可否が判断されます。条件部がなく固定で権限が設定されていた場合は、指定された権限が適用されます。
アップロード更新と併用する場合の注意点
条件付き閲覧権限を設定したモデルのデータをCSV形式ファイルでダウンロードした場合、これを編集してアップロード更新する運用には配慮が必要です。
以下のモデル定義を例に説明します。
| 項目 |
説明 |
| id | 主キー |
| a | |
| b | 条件付き閲覧権限を指定。項目aが"0"の場合にのみ閲覧可 |
次のようなデータを想定します。
データ1:id:1000 a:0 b:aaa
データ2:id:1001 a:1 b:bbb
権限を有したアカウントでログオンし、このモデルのデータをダウンロードすると、下記のようなCSVとなります。
(id),(a),(b)
1000,0,aaa
1001,1,
条件付き閲覧権限によって、"id=1001" のデータの b 列は、空になっています。(条件を満たさないため閲覧不可)
この状態で、"id=1001" のデータの a 列を 1 から 0 に修正し、CSVアップロード更新します。
このとき、列 b の値が (本来、データベースには保存されている "bbb" から) "から文字" に更新されるということを配慮する必要があります。
この問題への対応は次のように行ってください。
- 条件付き権限を含むモデルのアップロード更新を行う場合には、常に管理者アカウントで実行する。
- 条件付き権限を含む項目は、CSVダウンロードの対象としない。
サーバにファイルを保存する
生成したCSVファイルを(Wagbyが稼働する)サーバの所定フォルダに保存することができます。「画面 > ダウンロード > ファイル取得方法」で設定します。
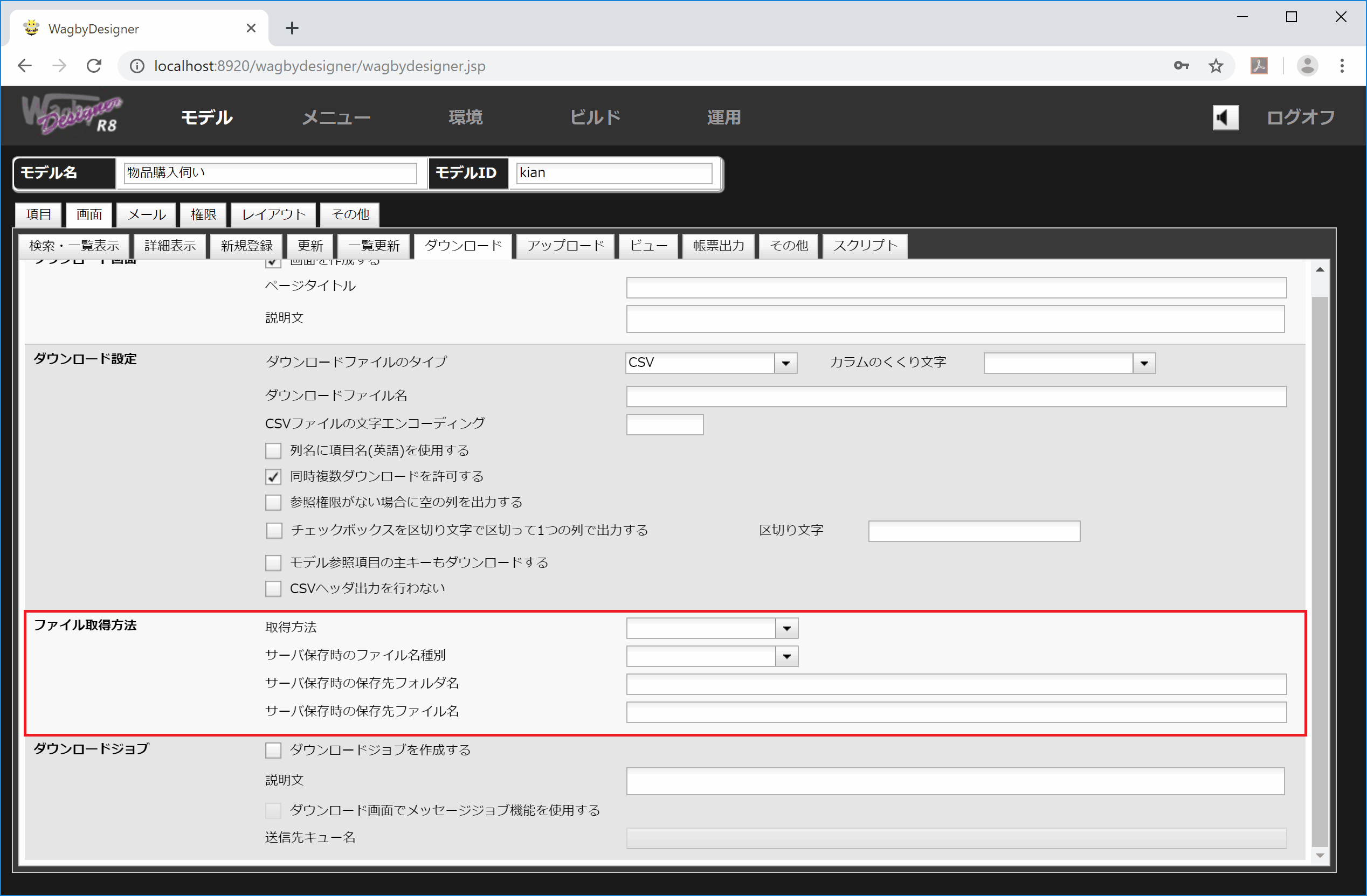 図18 ファイル取得方法に関する設定
図18 ファイル取得方法に関する設定
| 設定欄 |
説明 |
記述例 |
| 取得方法 |
"download" と "local" を選択できる。標準は "download" だが、"local" にするとサーバに保存される。 |
- |
| 保存先ファイル名 |
取得方法が "local" の場合に有効。保存するファイル名。保存先は本番運用サーバ。
指定がない場合は wagbyapp\tempフォルダに、download_xxx.csvというファイル名で出力される。(xxxはランダムな文字列。) |
C:\Downloads\YOURFILE.csv
/home/wagby/YOURFILE.csv |
| 保存先フォルダ名 |
取得方法が "local" の場合に有効。保存先ファイル名が指定されていない場合に用いる。指定されたフォルダ名に保存する。ファイル名は「ファイル名種別」の指定に準じる。 |
C:\Downloads
/home/wagby |
| ファイル名種別 |
ファイル名種別。未指定、temp、filename、extを指定できる。
未指定、tempの場合は一時ファイル名として、download_[ランダムな文字列].csvとなる。必ず一意になる。現状のダウンロードジョブと同様。tsvやxlsなどcsvでない形式を選択しても、拡張子は.csvとなる。
filenameの場合はDesignerで設定されたファイル名で保存する。拡張子も指定した形式に対応して設定される。
extの場合は拡張子はfilenameと同様に指定した形式に対応して設定されるが、拡張子を除くファイル名はtempと同様に必ず一意になるファイル名が設定される。 |
temp
filename
ext |
iPadでダウンロードする場合
文字エンコーディングの指定
iPad上のブラウザでWagbyアプリケーションを利用する場合、CSVファイルの文字エンコーディングを"UTF-8"に変更してください。
ワンポイント
iPadでは、ダウンロードしたCSVファイルをEvernoteやNumbersなどの(CSVファイルを扱える)他のアプリケーションと連携することにより、保存や編集を行うことが可能となります。
この設定を行うと、アプリケーション内のすべてのCSVダウンロードの文字エンコーディングがUTF-8となります。通常、ExcelはUTF-8形式のCSVファイルに対応していないため、iPadでは表示できるようになりますが、Excelで開くときには一工夫、必要になります。(検索エンジンにて "excel utf-8 csv" で探すと、多くのアドバイスを見つけることができます。)
ブラウザの戻るボタンの利用
iPadからCSVダウンロード機能を利用する場合、ダウンロード画面からCSVファイルを表示した画面に遷移するためにブラウザの「戻るボタン」を押す必要があります。
多言語対応
CSV ファイルの文字エンコーディングの標準は Windows-31J となっています。これは日本語環境のみに対応しています。
多言語のデータを含む場合、このモデルの文字エンコードを utf-8 に変更してください。
注意
ダウンロードしたファイルを Excel で開くときには注意が必要です。Excel は utf-8 形式の CSV ファイルに対応していないため、工夫が必要です。検索エンジンにて "excel utf-8 csv" で探すと、多くのアドバイスを見つけることができます。
ログ情報
ダウンロード処理に関するログには、ヒープメモリの状況が記録されます。
used=859.01 Mbyte (859,012,384 bytes.) max=2,075.92 MByte (2,075,918,336 bytes.) rate=41.38 %
これはダウンロード処理に限定したものではなく、このアプリケーション (wagbyapp) が利用しているヒープメモリを指します。used は現在の利用サイズで、max はこの wagbyapp の利用できるサイズの上限値です。ダウンロード開始時 ("start" と記録) と終了時 ("finished" と記録) で used の値を比較することができます。一般的にはダウンロード処理の途中で一時的に used が増えることがありますが、終了後は元に戻ります。
トラブルシューティング
テキストエリア項目をExcelに出力したとき、改行コードが消えているようにみえる。
Excel (XLSやXLSX形式)では、列の高さがデフォルトの1文字分の高さとなっているため、セルに改行がないようにみえます。セルにカーソルを合わせると、改行が含まれていることが分かります。
このテキストエリア項目に対応したセルに、セルの書式設定 - 配置 - 文字の制御にある「折り返して全体を表示する」を設定すると改行を含めてセルが表示されるようになります。
IE11利用時、ダウンロード時の保存、ファイルを開くボタンを素早く押すと"ファイルが移動または削除された可能性があります"というダイアログが表示される。
ファイルのダウンロードが終了する前にエクセルファイルが立ち上がっている可能性があります。「ファイルを開く、保存、キャンセル」のダイアログは IE が出力するもので Wagby では制御することができません。このようなメッセージが出力されたあと、数秒ほど待って実行すると問題ないようです。
参考:Excelが提供する「データ取り込み」機能の使い方
- Excel を開きます。メニューバーの「データ」−「外部データの取り込み」−「データの取り込み」をクリックします。
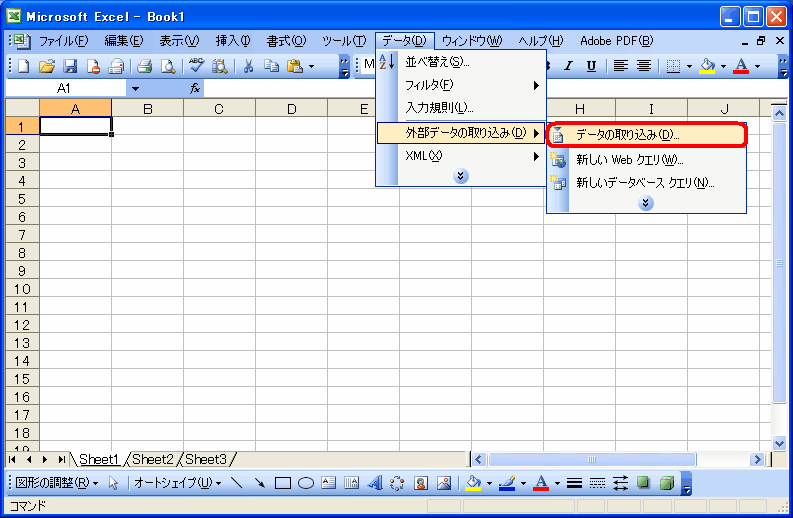 図19 Excelを開きデータを取り込む
図19 Excelを開きデータを取り込む
- 「データファイルの選択」で任意の CSV(TSV)ファイルを選択します。
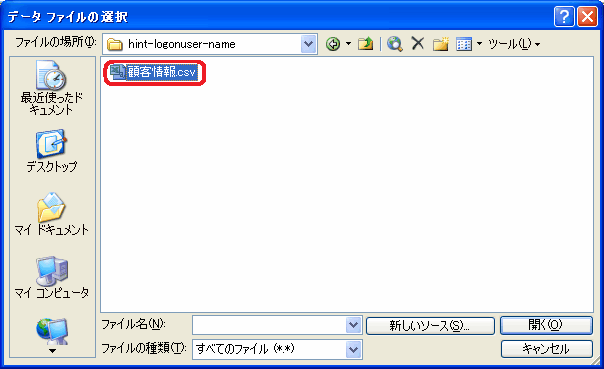 図20 Excelを開きデータを取り込む
図20 Excelを開きデータを取り込む
- 「テキストファイルウィザード」でデータを確認します。
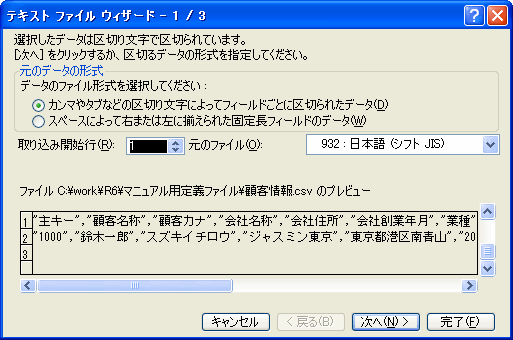 図21 テキストファイルウィザード(1)
図21 テキストファイルウィザード(1)
- 「区切り文字」で「カンマ」を指定します。(TSV ファイルの場合は「タブ」を指定。標準で指定されています。)
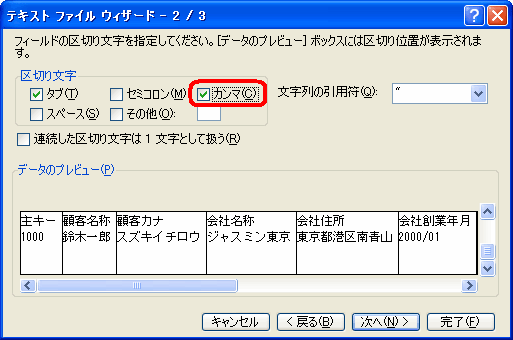 図22 テキストファイルウィザード(2)
図22 テキストファイルウィザード(2)
- 「データのプレビュー」で指定する列を選択し、「列のデータ形式」を指定します。(ここでは表示形式をそのまま表示するよう「文字列」と指定しました。)
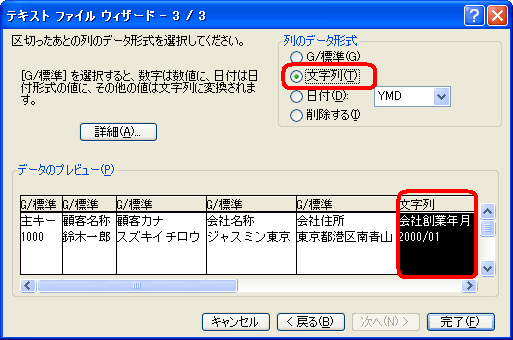 図23 テキストファイルウィザード(3)
図23 テキストファイルウィザード(3)
- データ取り込み完了です。指定した表示形式で表示されていることが分かります。
 図24 データ取り込み完了
図24 データ取り込み完了
仕様・制約
対応していない型
参照連動型項目の参照先が繰り返し、およびチェックボックスに対応していません。(出力されません。)
出力フォーマットの扱い
Excel形式出力の場合、Wagbyで設定した数値や日付の出力フォーマットは適用されません。Excelのセルのフォーマットが適用されます。
子モデル操作の制約
データベース非保存項目で、自モデル(親)に紐づく子モデルの値を取得する計算式は処理されません。例えば親モデルのDB非保存項目item1の式がCOUNT(${child_lp})であった場合、この項目は常に0になります。この理由は、親モデルの1データのダウンロード処理で、紐づく子モデルをすべて読み込むとパフォーマンス低下につながるためです。
代替案として次の方法を行なってください。