アップロード更新
最終更新日: 2025年4月1日
アップロード更新機能は、1行目にヘッダ(項目名)が含まれていることが前提となります。ヘッダはダウンロード機能で出力されます。
対象データの主キーが順序を利用する設定の場合、データの主キー項目を "-1" にすることで順序が適用されます。(自動採番処理)
データの削除を行うには、アップロードするファイルに「<Status>」という列を追加します。
図2では、主キーが 1007 のデータを削除するように指定しています。
処理の詳細
更新
新規登録

削除

注意
<Status>列は自動では付与されません。必要に応じて手動で付与してください。
<Status>列にはデータを新規登録・更新・削除のいずれかを識別するための文字(命令)を設定することができます。
| 識別文字 | 処理 | 内容 |
|---|---|---|
| i | 新規登録 | 新規にデータを登録します。 |
| u | 更新 | データを更新します。なお、主キーに対応するデータがない場合はエラーとなります。 |
| d | 削除 | データの削除を行います。 |
| n | なし | 何も処理を行いません。 |
| 空文字 | 通常と同じ処理 | 主キーに対応するデータがある場合は更新、ない場合は新規登録を行います。 |
ロックとコミット単位
(Wagby標準の)悲観ロックを利用している場合、更新処理と削除処理で1件ずつ、ロックの取得と解放が行われます。
またコミットは1行(1データ)単位です。
エラーの扱い
アップロード更新の途中にエラーが発生した場合、エラーが発生した行はスキップされます。全体の処理は継続されるため、それ以降の行はアップロード更新されていきます。
読み取り専用項目の扱い
読み取り専用項目はアップロード更新の対象から除外されます。(設定によって変更することができます。)
入力チェック
アップロード更新では、リポジトリで指定した入力チェック(「警告」を含む)が適用されます。
データの形式エラー(必須チェックや、数値を入力すべきところに非数字を設定した等)が発見された場合、画面にエラーデータの行番号とエラーメッセージが表示されます。データは更新(登録)されません。エラーのないデータのみが更新(登録)されます。
注意
「警告」を指定した場合も本チェックは適用されます。つまり該当データはアップロード更新処理で失敗と扱われます。
※ 登録画面では警告となるデータを登録し、これをCSVダウンロードでダウンロードした場合、ダウンロードしたデータをそのままアップロードしても警告が含まれているデータのためエラーとなって更新できません。ここで警告となった項目(列)を除いてアップロードしても同様にエラーとなります。すなわち、警告となった項目の値を(警告が出ないように)修正しないと、他の項目の修正も行うことはできません。親子モデル関係における、親モデルからみた子モデルの扱い
対象モデルに子モデルが紐づいており、自動計算式や入力チェックで子モデルの値を参照するような場合、アップロード更新では「子モデルなし」とみなして処理されます。
これはデータ1件を処理する毎にデータベースから関連する子モデル情報をすべて呼び出すことはパフォーマンスに影響を及ぼすための措置です。
親子モデル関係における、子モデルの単独アップロード
子モデルを新規登録する場合、親モデルの存在チェックは行いません。そのため、親が存在しない子のデータを作成することができます。
モデル参照項目の扱い
ダウンロード機能の設定で「モデル参照項目の主キーもダウンロードする」を有効にすると、参照先モデルの主キーで更新することができるようになります。
id 列と項目列の両方が設定された場合は、項目列(内容部)が優先されます。id 列の値で更新する場合、項目列を(手動で)削除してください。
参照先モデルが複合キーの場合
- 上で説明した「モデル参照項目の主キーもダウンロードする」を有効にします。
- id 列(「項目名#id」)と項目列の両方を含むファイルをダウンロードします。
- 項目列を削除します。id列で更新するためです。
- id 列の値に、複合キーを "$SEP$" で連結して設定します。例えば項目 pkey1 と pkey2 で複合キーを構成するモデルで pkey1 の値が 1000 、pkey2 の値が ABC だった場合、アップロードするファイルの id 列の値を "10000$SEP$ABC" と記述します。
モデル参照項目の内容部に適用されるフィルタ
アップロード更新でも(画面入力と同様)フィルタが適用されます。 モデル参照項目の内容部文字列には、参照項目先のフィルタ設定が用いられます。
ワークフロー動作中のデータ
ワークフロー動作中のデータは、アップロード更新での更新と削除が行えません。(更新しようとした場合、"ワークフローの状態により更新(削除)できません。" というエラーとなります。)
制約
対応していない型
- 参照連動型項目の参照先が繰り返し、およびチェックボックスの場合には未対応です。(更新されません。)
主キーがモデル参照項目の場合
- 主キーにモデル参照を指定している場合、アップロードするCSVファイルに含まれるこの主キー値は、参照先モデルのデータを指します。この参照先データが必ず存在している必要があります。
- 主キーにモデル参照を指定し、かつモデル参照(絞込)を適用したとき、未入力のときの動作に "選択肢を作らない" の設定を行うことはできません。この場合は "絞込条件にしない" を指定してください。
BOMの扱い
- R9.1.12/R9.2.8/R9.3.1より、BOM つきの CSV ファイルをアップロードすることに対応しました。これより前のバージョンのWagbyをお使いの場合は、BOMを除去したCSVファイルをアップロードしてください。
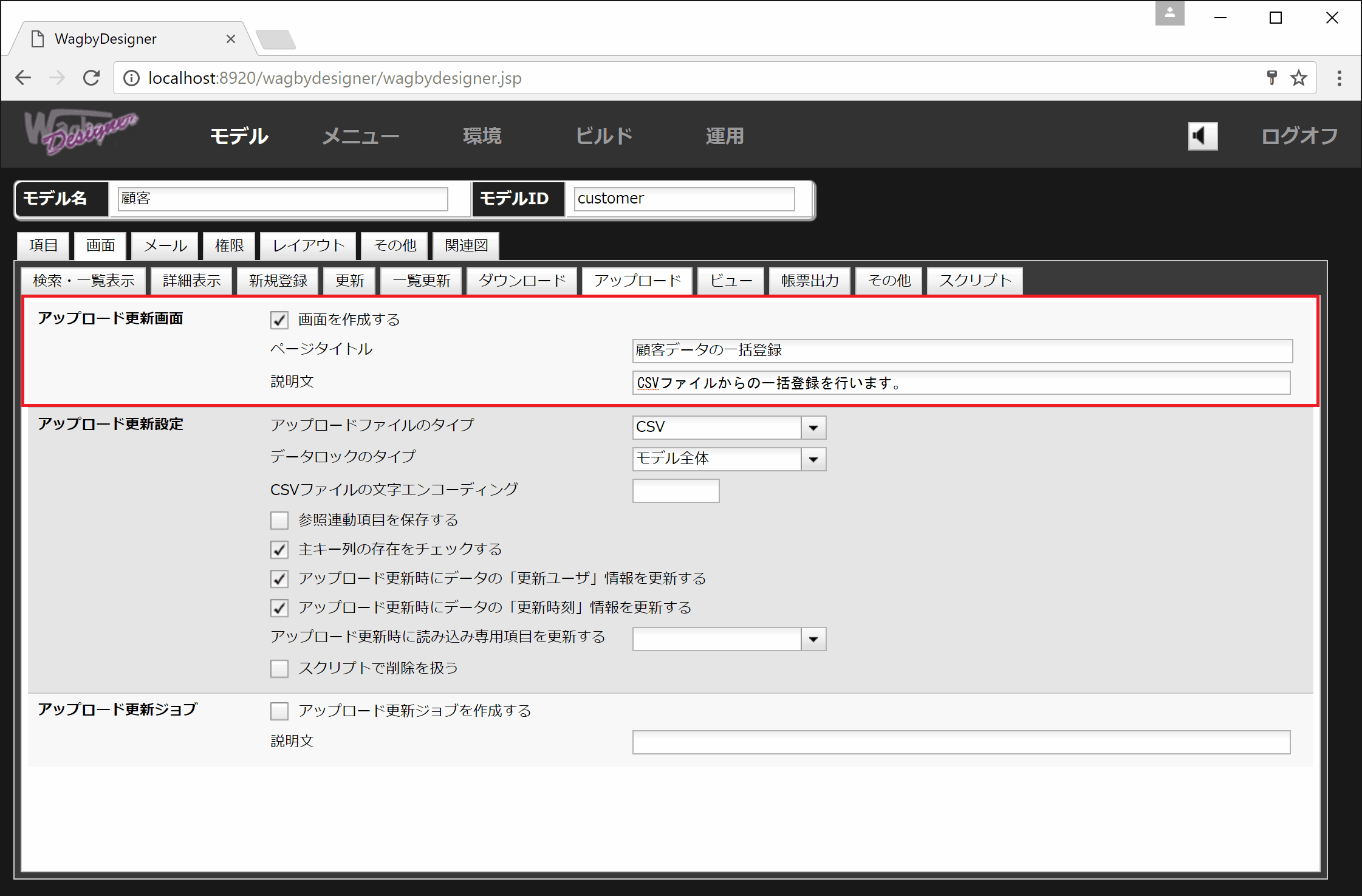
アップロード更新画面の設定
定義方法
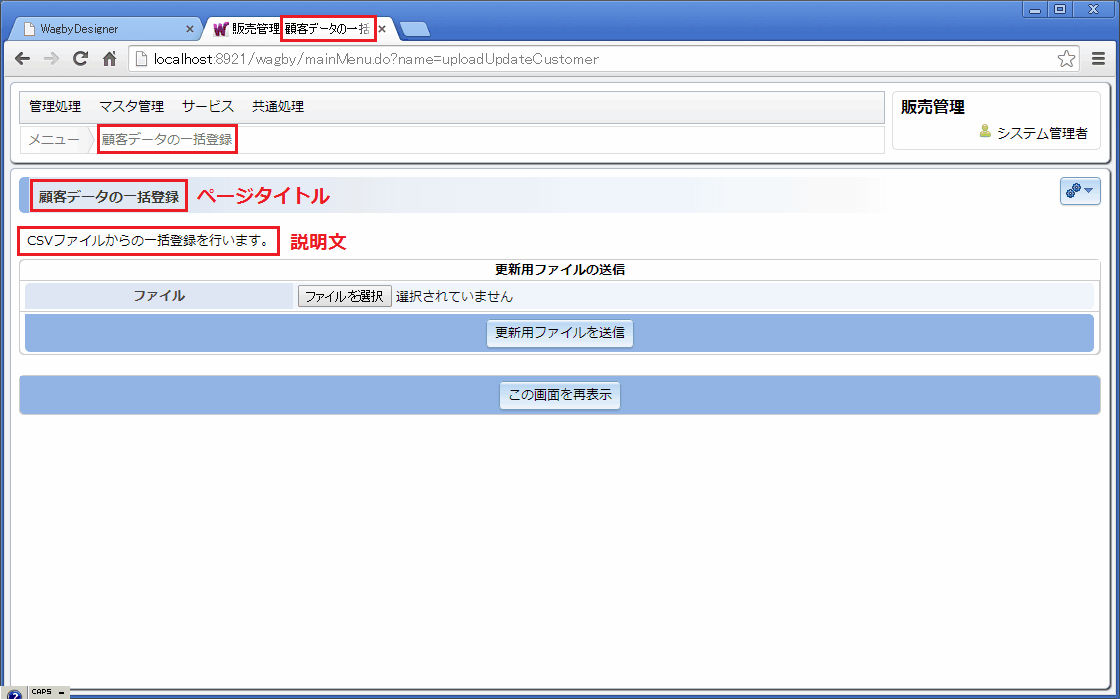
ページタイトルと説明文を指定することができます。(図3)
例
図3の設定で生成された画面を図4に示します。
アップロード更新機能の設定
アップロード更新設定の詳細を説明します。
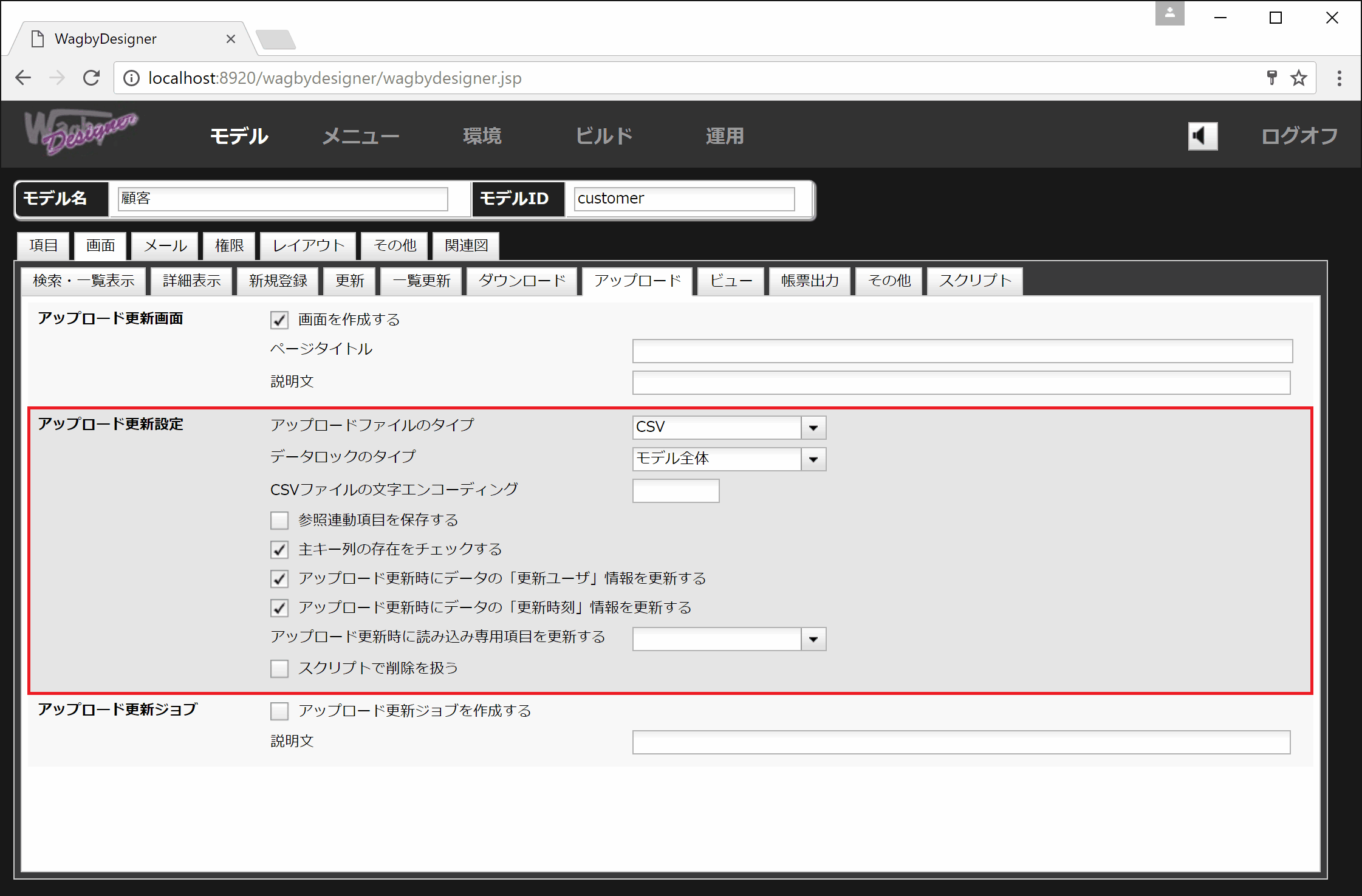
アップロードファイルのタイプ9.2.7
アップロードファイルは次のルールによって判定されます。
| ファイルの拡張子 | 説明 |
|---|---|
| csv | CSV(カンマ区切り)として処理する。 |
| tsv | TSV(タブ区切り)として処理する。 |
| xls または xlsx | Excel 形式のファイルとして処理する。 |
| 上記以外 | 「アップロードファイルのタイプ」で指定された方式と解釈して処理する。 |
たとえばファイルの拡張子をCSVとしたとき、TSVのファイルをアップロードするとエラーとなります。
データロックのタイプ
アップロード更新のロックは次の二通りから選択できます。
| 方式 | 説明 |
|---|---|
| モデル全体 |
本処理を実行している間、対象モデルのデータはすべてロックされます。
|
| レコード毎 |
データを更新しているユーザがいるときでも、本機能を同時に行うことができます。
|
いずれの方式でも、検索や一覧・詳細表示などの閲覧系ならびに新規登録は(本処理の実行中でも)行うことができます。
CSVファイルの文字エンコーディング
モデル毎にアップロードファイルの文字エンコードを指定することができます。この値が空白のときは「環境 > アプリケーション > 初期パラメータ > CSVファイルの文字エンコーディング」の値が用いられます。
参照連動項目も保存する
モデルに「参照連動項目を自モデルに保存する」設定を行っている項目が含まれていた場合、本設定を有効にするとアップロード更新でも自モデル保存機能を有効にすることができます。
主キー列の存在をチェックする
本機能はアップロードファイルに新規登録データと更新データを混在させることができます。そのため主キー列の存在をチェックしています。具体的には次のように動作します。
- 主キー値は設定されていないが、それ以外のいずれかの列に値が設定されている場合。エラーとします。"必須項目となっています" というメッセージが画面に表示されます。
- 主キー列そのものが存在しない場合。エラーとします。"CSVファイルのヘッダ行が不正です" というメッセージが表示されます。
- すべての列の値が未設定(空行)の場合。エラーではありません。この行の処理をスキップします。
アップロードデータが全て新規登録データで更新は行わないという運用を行う場合、この主キー存在チェックを行わないようにすることができます。
重要
ご注意ください:本設定を無効(主キー存在チェックを行わない)とした場合、主キー項目は必ず人工キー(順序)を適用するように設定してください。
アップロード更新時にデータの「更新ユーザ」情報を更新する
本設定が有効の場合、「固定値 - 更新ユーザ」は(アップロード更新を処理したユーザに)更新されます。これを更新させない運用を行う場合、本設定を解除してください。
ただし「アップロード更新時に読み込み専用項目を更新する」を許可し、かつ、アップロードファイルに「更新ユーザ」が含まれている場合は、アップロードファイル中のデータを "正" として、その値に更新します。
アップロード更新時にデータの「更新時刻」情報を更新する
本設定が有効の場合、「固定値 - 更新時刻」は(アップロード更新が処理された日付時刻に)更新されます。これを更新させない運用を行う場合、本設定を解除してください。
ただし「アップロード更新時に読み込み専用項目を更新する」を許可し、かつ、アップロードファイルに「更新時刻」が含まれている場合は、アップロードファイル中のデータを "正" として、その値に更新します。
アップロード更新時に読み込み専用項目を更新する
登録画面または更新画面のいずれかが読み込み専用となっている項目は、アップロード更新の対象外となります。
この設定を有効にすると、登録画面または更新画面のいずれかが読み込み専用であった場合でも更新されるようになります。選択肢は次のとおりです。
| 設定欄 | 説明 |
|---|---|
| (空白) | プロジェクト定義の設定に従う(標準は「× (許可しない)」) |
| ○ | 更新を許可する |
| × | 更新を許可しない |
スクリプトで削除を扱う
項目の設定
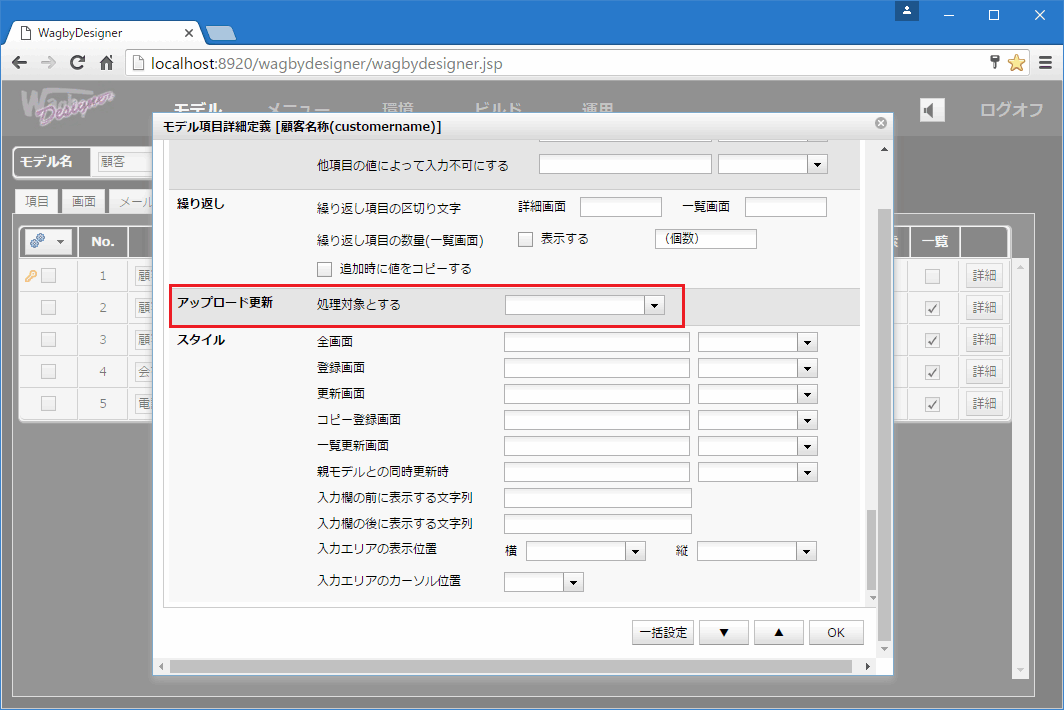
アップロード更新の対象に含める
各項目をアップロード更新の対象に含めるかどうかを個別に指定できます。
「モデル項目詳細定義>入力制御>アップロード更新」の「処理対象とする」を制御します。標準では空白となっています。
| 処理対象の指定 | 説明 |
|---|---|
| (空白) ※標準 | 「出力制御 - その他 - CSV - CSVに出力する」の値を使います。[後述] |
| ○ | アップロード更新の処理対象項目となります。上記「CSVに出力する」の値は考慮しません。 |
| × | アップロード更新の処理対象項目となりません。上記「CSVに出力する」の値は考慮しません。 |
CSV出力の設定
上記設定欄が「空白」の場合、「モデル項目詳細定義>出力制御>その他」の「CSVに出力する」によって制御されます。これは標準では有効となっています。

ワンポイント
つまり標準では "処理対象とする" が空白で、"CSVに出力する" が有効のため、アップロード更新対象として解釈されます。さらに、ダウンロードとアップロード更新の有効・無効をそれぞれ指定することができます。
注意
自動計算式が設定されている場合はアップロード更新の処理対象となりません。
モデル参照項目(検索画面)の存在チェックを行う
モデル参照項目(検索画面)の「入力制御 > 値を直接入力できるようにする」を有効にすると、アップロード更新でも存在チェック機能が有効になります。
処理件数の扱い
処理件数は「登録」「更新」「削除」「エラー」の行数の合計になります。
入力チェックエラーにおけるエラーメッセージ
例えばアップロード更新でエラーが発生し、そのメッセージが次の内容とします。
"2-4 行目 : 1 の項目に 1 を入力することはできません。"
これはヘッダ行込みの行数表示です。エラー処理結果ファイルをダウンロードした場合も同様に行数表示となっています。
この理由は、アップロードしたCSV/Excelファイルの実際の行番号と、エラー行を一致させるためです。(どの行がエラーか、を把握しやすくするため、です。)
エラー時の動作
特定行のみエラーの場合
特定の行にエラーが含まれていた場合、当該行のみ処理がスキップされます。次の行へと処理を継続します。
致命的なエラーの場合
致命的なエラー(ファイルの破損、ダブルクォーテーションの整合性がとれていない)に遭遇した場合、その時点で処理は停止されます。このとき、エラー行の前までは更新されます。エラー行以降は処理がスキップされます。
更新結果レポートの確認
「すべての処理結果をダウンロード」と「エラー処理結果をダウンロード」のリンクをクリックすることで、それぞれの結果をファイルでダウンロードすることができます。
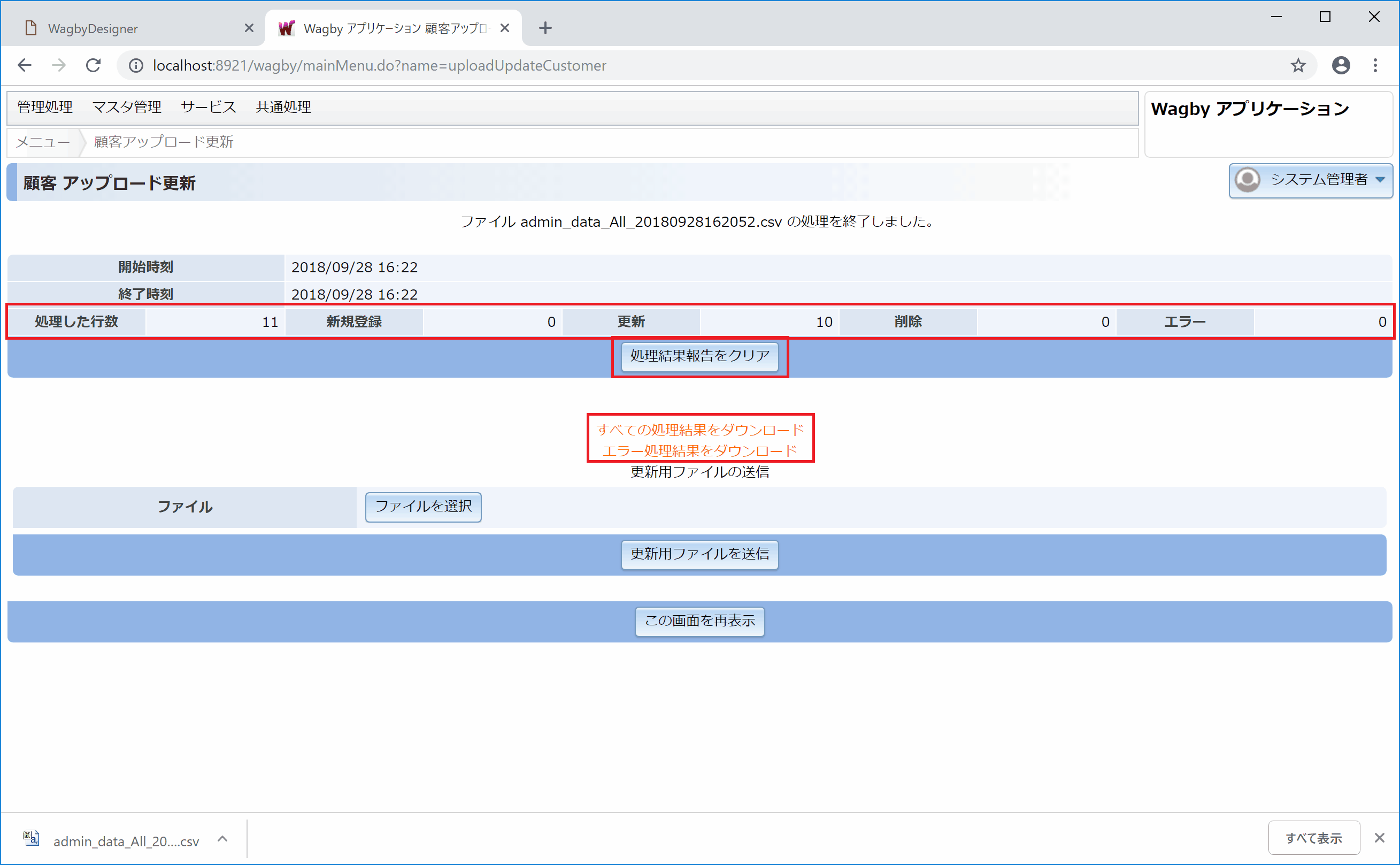
処理結果レポートの確認
「すべての処理結果をダウンロード」のリンクをクリックするとファイルをダウンロードできます。 ファイル名は "process_モデル名" となっており、中身はテキストファイルです。Excelを使って開いた例を図9に示します。

アップロードしたデータ全件について<Success>,<Process>,<Message>という列で結果を確認できます。それぞれ次のような意味です。
| 列名 | 説明 |
|---|---|
| Success | 処理の成功、失敗を表します。成功の場合は "Success"、失敗の場合は "Error" と出力されます。 |
| Process | 新規登録は "Insert"、更新は "Update"、削除は "Delete"、何も行われていない場合は "None" と出力されます。 |
| Message | エラー内容が出力されます。複数のエラーがあった場合は改行して出力されます。 |
二行目(赤枠部)は「どの列が処理されたか」を示す情報です。処理対象となった列に "○" が表示されています。(※注)
エラー処理レポートの確認
「エラー処理結果をダウンロード」のリンクをクリックするとファイルをダウンロードできます。 ファイル名は "error_モデル名" となっており、中身はテキストファイルです。Excelを使って開いた例を示します。 ここではエラーがないため2行目以降は空行となっています。

エラーがあった場合は <Success> の列に "Error" が設定されます。<Message>にはエラー内容が出力されます。
警告メッセージの場合
<Message> 列に警告メッセージが出力されます。その中に、項目名を含む警告メッセージが出力されます。

処理結果レポートのクリア
「処理結果報告をクリア」ボタンを押下することで、前回の処理結果レポートを消去することができます。
独自に用意したファイルをアップロードする
Wagby のダウンロード機能で取得したものではない、オリジナルのCSVファイルもアップロード更新に用いることができます。次のルールを適用するようにしてください。
- 先頭(1 行目)は日本語の項目名を記載します。項目名はダウンロード機能で取得する形式と同じものとします。異なる項目名を使用した場合は、正しく更新されません。
- データ中に 「"」, 「'」, 「(改行)」のいずれかが含まれる場合、そのデータ全体を引用符 「"」で囲むようにしてください。これはCSVファイルの仕様です。
- データ中に含まれる「"」は「""」へと置換してください。これはCSVファイルの仕様です。
ワンポイント
Excel が提供する「CSV形式で保存」機能を使うことで、上記で示したルールに基づく(引用符「"」を正しく考慮した)CSV ファイルを用意することができます。
注意
リポジトリの設定によってはヘッダ行の項目名とデータベースのカラム名が同一とならない場合があります。
このため独自にアップロード更新用ファイルを用意する場合は、一度ダウンロード機能を実行し、アップロード更新対象となる項目名が完全に合致するかどうかを確認するようにしてください。
複数のファイルをzip圧縮して送信する
複数の csv (または tsv) 形式のファイルを 1 つの zip ファイルに圧縮し、これをアップロード更新することができます。次のルールが適用されます。
- 同じモデルに関するデータを複数の CSV ファイルに分割して登録できます。
- ファイル名のアルファベット順に処理されます。
- zip ファイル内に処理可能なファイルが一つも含まれていない場合は、エラーメッセージを表示して終了します。
- エラーがあった場合、エラーメッセージの先頭に処理対象ファイル名を記載します。これによって、どのファイルでエラーが生じたかがわかるようになっています。
重要
zip ファイル内に Excel ファイルを含めることはできません。(Excel ファイルは無視されます。)
zip ファイル内に csv 形式および tsv 形式ファイルを混在させることもできます。ファイルの拡張子で判別します。
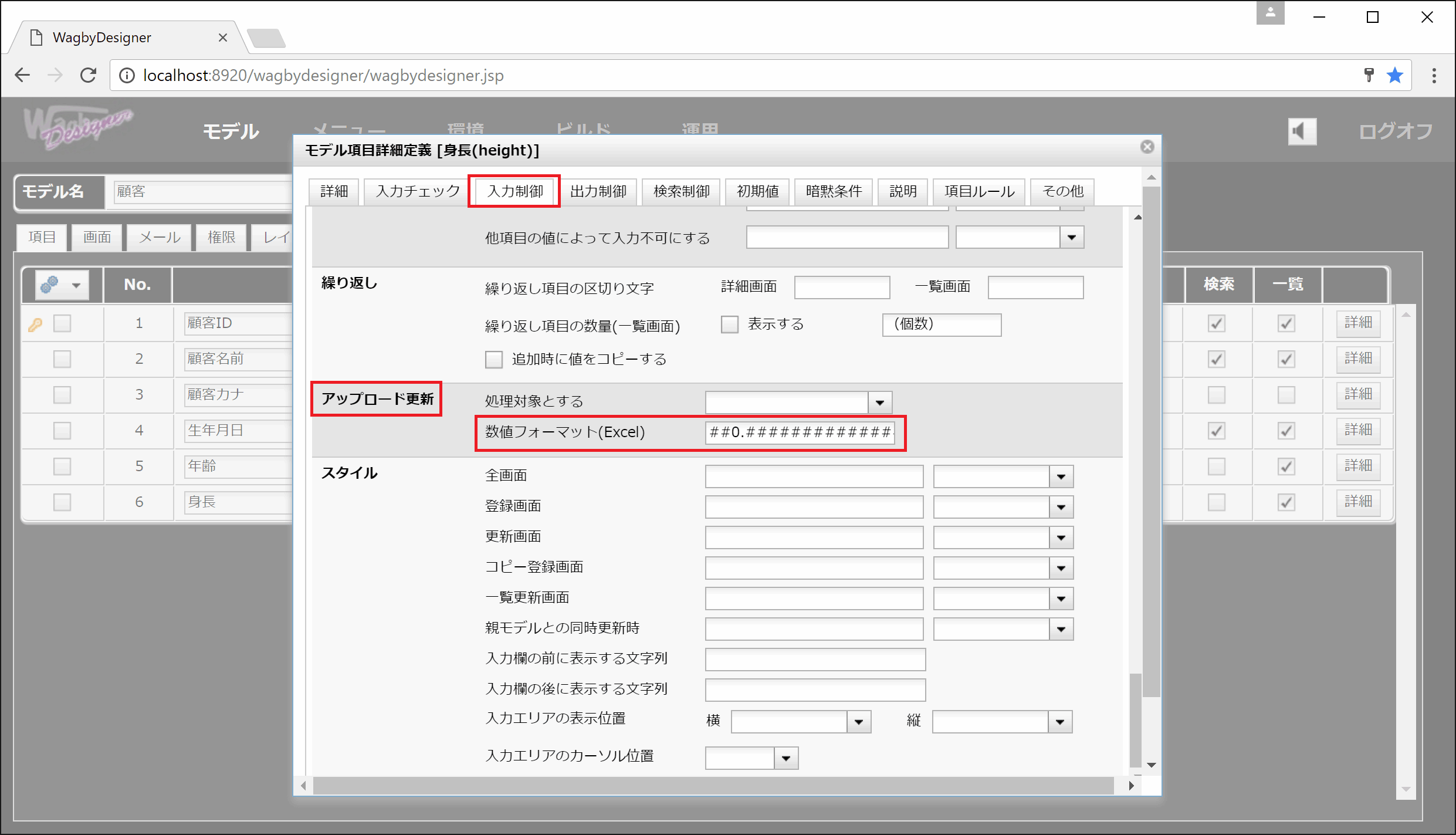
Excel利用時に数値フォーマットを指定する
Excelファイルを使ったアップロード更新時に、数値項目の解析に使う数値フォーマットを指定できます。 未指定の場合は "##0.###" という固定フォーマットが用いられます。これは小数点3桁までの値を取り込むようになっています。
定義方法
モデル項目の「入力制御 > アップロード更新 > 数値フォーマット(Excel)」を指定します。次の例は小数点以下17桁まで入力するように設定しています。
##0.#################
ワンポイント
この設定は、CSVファイルを用いたアップロード更新には影響しません。(CSVファイルを用いたアップロード更新では、入力値はそのまま用いられます。)
ログオンセッションの数え方
CSV/Excelアップロード更新は処理の最初に内部でログオン処理を行なっています。これにより、ライセンス制限上のログオン数を超えた場合は注意が必要です。
例えば1つのログオンアカウント(ユーザー)で同時に5モデルのアップロード更新を行った場合、ログオン数は6とカウントされます。
このとき、1アカウントのログオン数上限を2と指定していた場合でも、上記のような5モデル同時アップロード更新の運用は行うことができます。すなわち、ライセンスによるログオン数の上限いっぱいまで、1アカウントで(アップロード更新処理で)消費してしまうといったことが可能です。
トラブルシューティング
アップロードされたファイルが不正
アップロードしたCSV形式ファイルが UTF-8 で保存されていませんか。
特定のデータが処理できない
次の点をご確認ください。
- データに不正な文字(特殊文字、外字など)が含まれていませんか。
- データが「一意制約チェック」に違反していませんか。
- CSV形式でダウンロードしたファイルをExcelで開き、その後、保存しましたか? Excel の仕様で、前詰めに "0" を含むデータは、その "0" が消えてしまいます。例えば、実際のデータが "000123" だった場合、このCSVファイルをExcelで開き、保存すると "123" となります。この値が主キーだった場合、該当データが見つからないという問題が生じます。 ※ これを防ぐために、Excel では「CSV取り込み」という機能があります。CSVファイルをダブルクリックするのではなく、ExcelのメニューからCSVファイルを読み込むようにすることでこの問題を回避できます。
- Excelファイルをアップロードする場合、アップロード対象のデータが「Excelの計算式」や「(別シート参照を含む)セル参照」の場合、正しい値を読み込めない場合があります。
注意
Excelファイルをアップロードする場合、式を使って表現されたデータをアップロードしないようにしてください。
特定の列が処理できない
- 特定の列だけ正しく処理されない場合、アップロードするファイルの先頭行の「列名」と、設計情報に記載した「列名」が正しく一致しているかどうかを確認してください。列名が完全に一致しない場合、その列の処理は行われません。
- 登録画面または更新画面のいずれかが読み込み専用となっている項目は、アップロード更新の対象外となります。[詳細...]
- 自動計算式が設定された項目は、アップロード更新の対象外となります。常に式を実行します。
- 「入力制御 > アップロード更新 > 処理対象とする」が有効でない項目は、アップロードの対象となりません。
ファイルアップロード途中でブラウザとの通信が中断した
大きなファイルを処理しようとして、通信経路内に指定されているタイムアウト値を超えた可能性があります。次の回避策を検討してください。
[事例] 新規登録が正しく処理されない
主キーに順序を利用したモデルについて、次のようなファイルをアップロードしました。なお、主キーは1000番から開始されるものとし、処理時にデータは1件も登録されていなかったとします。
pkey, name
1000, aaa
1002, bbb
1001, ccc
このとき、次のような動作となります。
- データは1件も登録されていない状態ですので、1行目は新規登録となります。ここで "1000" という値は使われず、順序から自動採番されます。たまたま、同じ "1000" が発番され、1行目の登録は成功します。
- 2行目も新規登録となります。ここで "1002" という値は使われず、順序から "1001" が発番され、登録されます。この時点でのデータベースの内容は次のとおりです。
1000,aaa 1001,bbb - 3行目はすでに "1001" というデータが登録済みのため、更新扱いとなります。よってデータベースの内容は次のように書き換えられます。
1000,aaa 1001,ccc
対策(1) : このような誤動作を防ぐため、順序を用いたモデルへの登録は主キー部分を "-1" と設定するとよいです。
対策(2) : アップロードするデータはあらかじめ主キーでソートしておくようにします。(例えばダウンロード機能でデータを取得する場合、主キーでソートさせたデータを使うといったルールを定めることで未然に回避できます。)
[事例] モデル参照項目の更新で、参照先の名称が異なっていた
例えば「会社」モデルを参照しているデータで、会社名に「山田商店」と記載していたが、実際の会社モデルにこのデータが存在しなかった場合、この項目そのものの更新が行われません。
[事例] モデル参照項目の更新で、無効なデータに更新しようとした
「選択肢モデル>選択肢を無効にする」設定で、あるデータを無効化(論理削除)していたとします。ここで、無効なデータに更新しようとした場合、更新エラーになります。
[事例] モデル参照(チェックボックス)型項目に対して必須入力チェックを指定している
すべてチェックしない状態でアップロード更新するとエラーとなります。一つ以上チェックしてアップロード更新するとエラーになりません。
[事例] 異なるコードに同じ内容(データ)を設定した
このようなデータが存在した場合は、無視またはエラー扱いとなります。例えば「性別」モデルに次のようなデータを設定したとします。
| コード | 値 |
|---|---|
| 1 | 男 |
| 2 | 女 |
| 3 | 男 !重複した内容 |
このとき、"女" から "男" へのアップロード更新はエラーになります。コード1と3のどちらを使えばいいか判断できないためです。
画面上には、次のようなエラーメッセージが表示されます。
項目 XXX に指定された値 YYY で問題が発生しました。同じコードに複数の値が定義されています。そのためどのコードを更新するか特定できません。[事例] データをアップロードしたとき、関係のないモデルも同時に更新される
アップロード対象が「子モデル」の場合、「画面 > その他 > モデルの関連性 > 変更時に親モデルも更新する」が有効の場合、親モデルも更新されることがあります。
さらに、その親モデルが他のモデルと関係性がある場合(例えば他の子モデルがあり、お互いを参照している)、関連するモデルも必要に応じて更新されることがあります。
[事例] 未選択を用意しないリストボックス
アップロード対象項目がモデル参照(リストボックス)で、「リストボックス利用時に "未選択" を用意する」設定が無効の場合、リスト候補の先頭が自動的に選択されたとみなされます。これは UI 操作と同じ処理が適用される仕様のためです。