入力フィルタの仕様
最終更新日: 2021年4月21日
Wagbyでは、入力された値は「フィルタ」によって補正されます。
フィルタにより「ゆれ」を自動的に補正することができます。この機能は自動的に設定されます。
入力値を「文字列」と判定するフィルタです。日本語が含まれる値が入る項目は「文字列(一般)」フィルタを選択することを推奨します。次のような処理が行われます。
すなわち、本指定は後述する「文字列(最小限)」「半角→全角」「全角→半角」を含んだものとなっています。
改行コードを "LF" (\n) に統一します。
入力値を日付と判断して、日付型に変換するフィルタです。全角で入力された数値はすべて半角に統一します。
入力値を数値と判断して、数値型に変換するフィルタです。全角で入力された数値はすべて半角に統一します。
入力値に半角文字が含まれていた場合、この半角文字に対応する全角文字に変換します。
入力値に半角カタカナが含まれていた場合、この半角カタカナを全角カタカナに変換します。
入力値に半角文字が含まれていた場合、この半角文字に対応する全角文字に変換します。半角空白も全角空白に変換します。
入力値に全角文字が含まれていた場合、この全角文字に対応する半角文字に変換します。対応する半角文字がなければ変換はされません。
入力値に全角文字が含まれていた場合、この全角文字に対応する半角文字に変換します。全角空白も半角空白に変換します。対応する半角文字がなければ変換はされません。
スクリプトを使用したユーザ独自の入力フィルタを設定するときに選択します。
フィルタを「なし」とすることはできません。この欄を空白とした場合、フィルタなしではなく、型に応じた標準のフィルタが自動選択されます。例えば文字列型の場合は「文字列(一般)」が適用されます。全角英数字や半角カナ文字をそのまま保存したい場合は「文字列(最小限)」を選択してください。
フィルタはWebフォーム、アップロード更新、REST APIいずれも共通で利用されます。
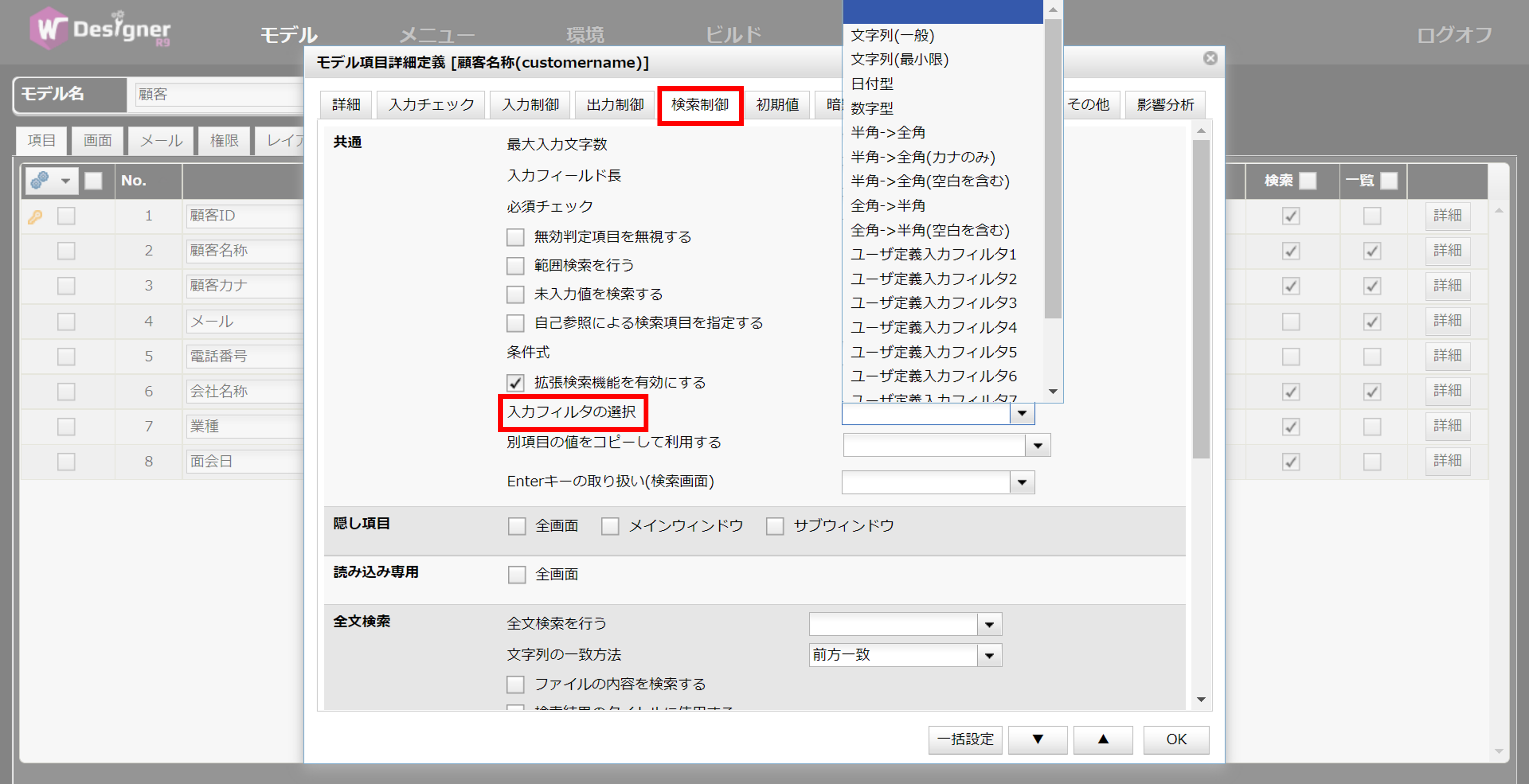
入力時(登録・更新画面)と検索画面でフィルタを個別に指定することができます。モデル項目詳細設定ダイアログの「検索制御」タブで「入力フィルタ」を指定できます。
各フィルタの詳細な仕様は次のとおりです。(数値はフィルタ処理の順番です。)
参照連動項目にもフィルタが適用されます。
詳細は"他モデルの参照 > 参照連動 > 参照連動項目の入力フィルタ"をお読みください。
入力フィルタの選択
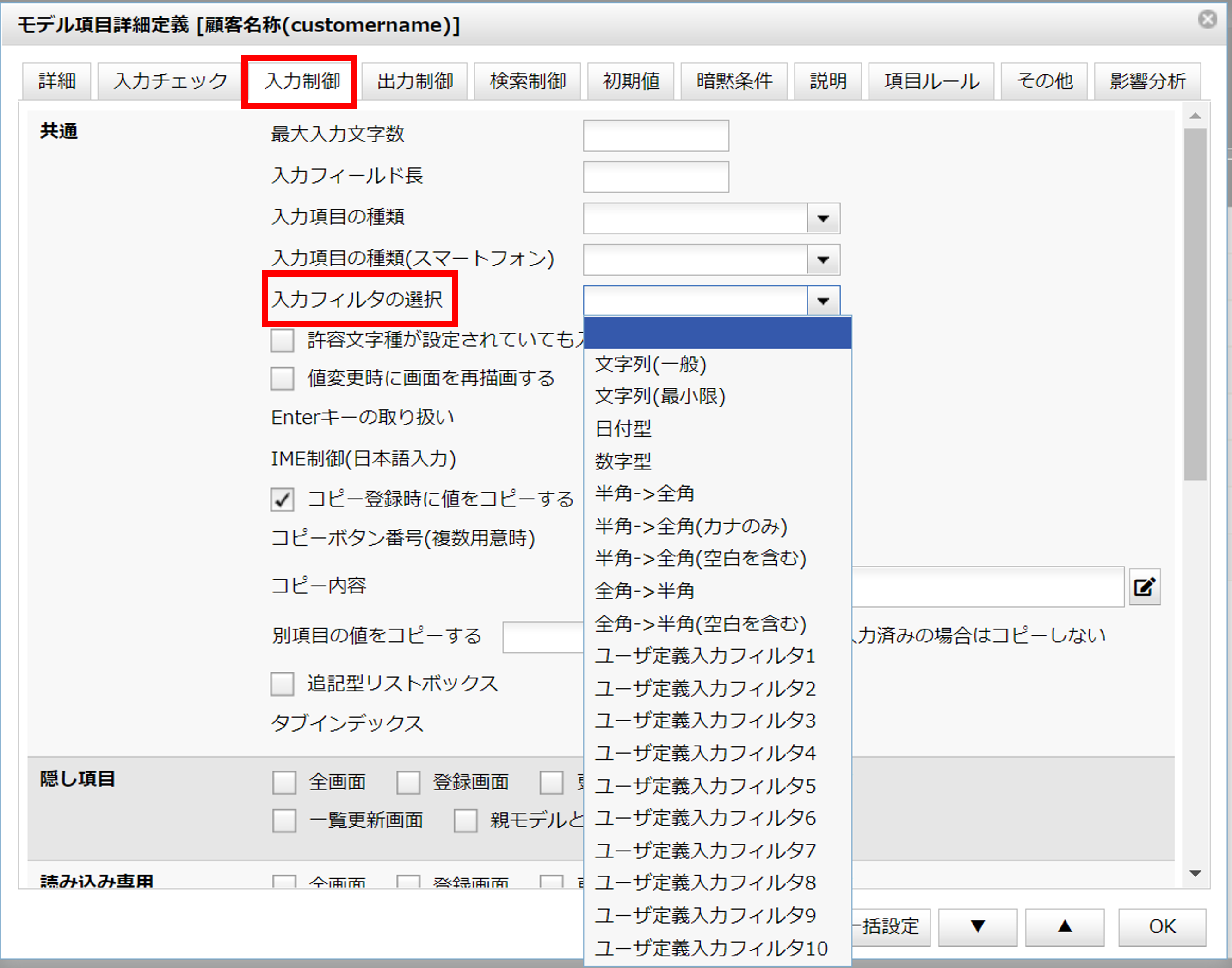
文字列(一般)
文字列(最小限)
日付型
数字型
半角→全角
半角→全角(カナのみ)
半角→全角(空白を含む)
全角→半角
全角→半角(空白を含む)
ユーザ定義入力フィルタWDN
設定方法は「WDN > スクリプト > 入力フィルタ」をお読みください。
注意
ワンポイント
検索時の入力フィルタ
詳細な仕様
文
文(小)
数
日
半→全
半→全(カ)
半→全(空)
全→半
全→半(空)
XML文字
1
1
1
1
1
1
1
1
1
空白除去
2
2
2
2
2
2
2
2
改行除去
3
2
3
3
3
3
3
3
3
英 全→半
4
4
4
4
英 半→全
4
4
数 全→半
5
4
5
5
5
数 半→全
5
5
記 全→半
6
5
6
6
6
記 半→全
6
6
仮 全→半
7
7
仮 半→全
7
7
4
7
マ 全→半
6
7
8
8
マ 半→全
8
8
正 半マ
9
9
正 全マ
8
7
8
9
9
空 全→半
10
空 半→全
10
参照連動項目の入力フィルタ
標準のフィルタルールを変更する